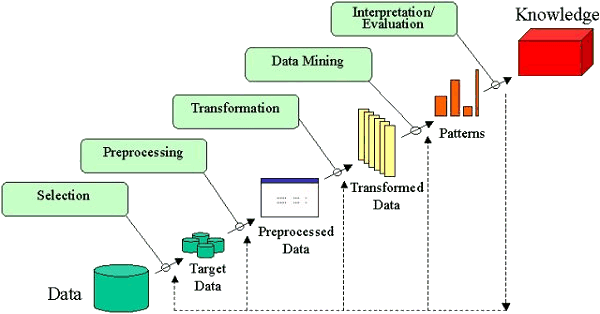
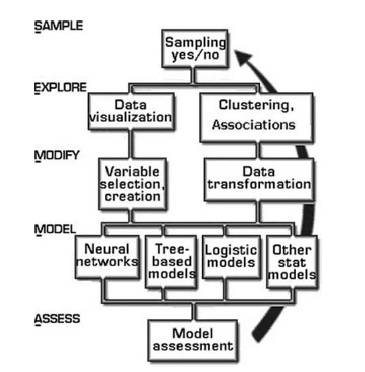
Continuing the DecisionStats series on trends for 2012, Timo Elliott , Technology Evangelist at SAP Business Objects, looks at the predictions he made in the beginning of 2011 and follows up with the things that surprised him in 2011, and what he foresees in 2012.
You can read last year’s predictions by Mr Elliott at http://www.decisionstats.com/brief-interview-timo-elliott/
Timo- Here are my comments on the “top three analytics trends” predictions I made last year:

(1) Analytics, reinvented. New DW techniques make it possible to do sub-second, interactive analytics directly against row-level operational data. Now BI processes and interfaces need to be rethought and redesigned to make best use of this — notably by blurring the distinctions between the “design” and “consumption” phases of BI.
I spent most of 2011 talking about this theme at various conferences: how existing BI technology israpidly becoming obsolete and how the changes are akin to the move from film to digital photography. Technology that has been around for many years (in-memory, column stores, datawarehouse appliances, etc.) came together to create exciting new opportunities and even generally-skeptical industry analysts put out press releases such as “Gartner Says Data Warehousing Reaching Its Most Significant Inflection Point Since Its Inception.” Some of the smaller BI vendors had been pushing in-memory analytics for years, but the general market started paying more attention when megavendors like SAP started painting a long-term vision of in-memory becoming a core platform for applications, not just analytics. Database leader Oracle was forced to upgrade their in-memory messaging from “It’s a complete fantasy” to “we have that too”.
(2) Corporate and personal BI come together. The ability to mix corporate and personal data for quick, pragmatic analysis is a common business need. The typical solution to the problem — extracting and combining the data into a local data store (either Excel or a departmental data mart) — pleases users, but introduces duplication and extra costs and makes a mockery of information governance. 2011 will see the rise of systems that let individuals and departments load their data into personal spaces in the corporate environment, allowing pragmatic analytic flexibility without compromising security and governance.
The number of departmental “data discovery” initiatives continued to rise through 2011, but new tools do make it easier for business people to upload and manipulate their own information while using the corporate standards. 2012 will see more development of “enterprise data discovery” interfaces for casual users.
(3) The next generation of business applications. Where are the business applications designed to support what people really do all day, such as implementing this year’s strategy, launching new products, or acquiring another company? 2011 will see the first prototypes of people-focused, flexible, information-centric, and collaborative applications, bringing together the best of business intelligence, “enterprise 2.0”, and existing operational applications.
2011 saw the rise of sophisticated, user-centric mobile applications that combine data from corporate systems with GPS mapping and the ability to “take action”, such as mobile medical analytics for doctors or mobile beauty advisor applications, and collaborative BI started becoming a standard part of enterprise platforms.
And one that should happen, but probably won’t: (4) Intelligence = Information + PEOPLE. Successful analytics isn’t about technology — it’s about people, process, and culture. The biggest trend in 2011 should be organizations spending the majority of their efforts on user adoption rather than technical implementation.
Unsurprisingly, there was still high demand for presentations on why BI projects fail and how to implement BI competency centers. The new architectures probably resulted in even more emphasis on technology than ever, while business peoples’ expectations skyrocketed, fueled by advances in the consumer world. The result was probably even more dissatisfaction in the past, but the benefits of the new architectures should start becoming clearer during 2012.
What surprised me the most:
The rapid rise of Hadoop / NoSQL. The potentials of the technology have always been impressive, but I was surprised just how quickly these technology has been used to address real-life business problems (beyond the “big web” vendors where it originated), and how quickly it is becoming part of mainstream enterprise analytic architectures (e.g. Sybase IQ 15.4 includes native MapReduce APIs, Hadoop integration and federation, etc.)
Prediction for 2012:
As I sat down to gather my thoughts about BI in 2012, I quickly came up with the same long laundry list of BI topics as everybody else: in-memory, mobile, predictive, social, collaborative decision-making, data discovery, real-time, etc. etc. All of these things are clearly important, and where going to continue to see great improvements this year. But I think that the real “next big thing” in BI is what I’m seeing when I talk to customers: they’re using these new opportunities not only to “improve analytics” but also fundamentally rethink some of their key business processes.
Instead of analytics being something that is used to monitor and eventually improve a business process, analytics is becoming a more fundamental part of the business process itself. One example is a large telco company that has transformed the way they attract customers. Instead of laboriously creating a range of rate plans, promoting them, and analyzing the results, they now use analytics to automatically create hundreds of more complex, personalized rate plans. They then throw them out into the market, monitor in real time, and quickly cull any that aren’t successful. It’s a way of doing business that would have been inconceivable in the past, and a lot more common in the future.
About

Timo Elliott is a 20-year veteran of SAP BusinessObjects, and has spent the last quarter-century working with customers around the world on information strategy.
He works closely with SAP research and innovation centers around the world to evangelize new technology prototypes.
His popular Business Analytics blog tracks innovation in analytics and social media, including topics such as augmented corporate reality, collaborative decision-making, and social network analysis.
His PowerPoint Twitter Tools lets presenters see and react to tweets in real time, embedded directly within their slides.
A popular and engaging speaker, Elliott presents regularly to IT and business audiences at international conferences, on subjects such as why BI projects fail and what to do about it, and the intersection of BI and enterprise 2.0.
Prior to Business Objects, Elliott was a computer consultant in Hong Kong and led analytics projects for Shell in New Zealand. He holds a first-class honors degree in Economics with Statistics from Bristol University, England
Timo can be contacted via Twitter at https://twitter.com/timoelliott
Part 1 of this series was from James Kobielus, Forrestor at http://www.decisionstats.com/jim-kobielus-on-2012/