Use cmd to get the terminal
Then type SET to get the environmental variables
C:\Users\AJAY>SET

Use cmd to get the terminal
Then type SET to get the environmental variables
C:\Users\AJAY>SET
https://github.com/decisionstats/sas-for-data-science/blob/master/split%20test%20and%20control.sas

| data cars; |
| set sashelp.cars; |
| run; |
| data cars2; |
| set sashelp.cars; |
| where ranuni(12) <=.25; |
| run; |
|
data cars2;
set sashelp.cars;
where ranuni(12) <=.25;
run;
NOTE: There were 114 observations read from the data set SASHELP.CARS.
WHERE RANUNI(12)<=0.25;
NOTE: The data set WORK.CARS2 has 114 observations and 15 variables.
|
| data cars3 cars4; |
| set sashelp.cars; |
| if ranuni(12)<=.25 then output cars3; |
| else output cars4; |
| run; |
|
data cars3 cars4;
set sashelp.cars;
if ranuni(12)<=.25 then output cars3;
else output cars4;
run;
NOTE: There were 428 observations read from the data set SASHELP.CARS.
NOTE: The data set WORK.CARS3 has 114 observations and 15 variables.
NOTE: The data set WORK.CARS4 has 314 observations and 15 variables.
|
| PROC SURVEYSELECT DATA=cars OUT=test_cars METHOD=srs SAMPRATE=0.25; |
| RUN; |
| PROC SURVEYSELECT DATA=cars outall OUT=test_cars2 METHOD=srs SAMPRATE=0.25; |
| RUN; |
|
PROC SURVEYSELECT DATA=cars OUT=test_cars METHOD=srs SAMPRATE=0.25;
RUN;
NOTE: The data set WORK.TEST_CARS has 107 observations and 15 variables.
NOTE: PROCEDURE SURVEYSELECT used (Total process time):
PROC SURVEYSELECT DATA=cars outall OUT=test_cars2 METHOD=srs SAMPRATE=0.25;
RUN;
NOTE: The data set WORK.TEST_CARS2 has 428 observations and 16 variables.
NOTE: PROCEDURE SURVEYSELECT used (Total process time):
|
| proc print data=test_cars2 (obs=6); |
| var selected; |
| run; |
| proc freq data=test_cars2; |
| tables selected/norow nocol nocum nopercent; |
| run; |
| data test ; |
| set test_cars2; |
| where selected=0 ; |
| run; |
| data control ; |
| set test_cars2; |
| where selected=1 ; |
| run; |

Output

Python Tpot offers automated machine learning.
From
Click to access olson_tpot_2016.pdf
Machine learning is commonly described as a field of study that gives computers the ability to learn without being explicitly programmed”(Simon, 2013). Despite this common claim, machine learning practitioners know that designing effective machine learning pipelines is often a tedious endeavour, and typically requires considerable experience with machine learning algorithms, expert knowledge of the problem domain, and brute force search to accomplish (Olson et al., 2016a). Thus, contrary to what machine learning enthusiasts would have us believe, machine learning still requires considerable explicit programming. In response to this challenge, several automated machine learning methods have been developed over the years (Hutter et al., 2015).Over the past year, we have been developing a Tree-based Pipeline Optimization Tool (TPOT) that automatically designs and optimizes machine learning pipelines for a given problem domain (Olson et al., 2016b), without any need for human intervention. In short, TPOT optimizes machine learning pipelines using a version of genetic programming (GP)


Citation: Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science
Randal S. Olson, Nathan Bartley, Ryan J. Urbanowicz, and Jason H. Moore (2016). Evaluation of a Tree-based Pipeline Optimization Tool for Automating Data Science. Proceedings of GECCO 2016, pages 485-492
library(rattle)## Rattle: A free graphical interface for data mining with R.
## Version 4.1.0 Copyright (c) 2006-2015 Togaware Pty Ltd.
## Type 'rattle()' to shake, rattle, and roll your data.library(party)## Loading required package: grid## Loading required package: mvtnorm## Loading required package: modeltools## Loading required package: stats4## Loading required package: strucchange## Loading required package: zoo##
## Attaching package: 'zoo'## The following objects are masked from 'package:base':
##
## as.Date, as.Date.numeric## Loading required package: sandwichdata(iris)
model=ctree(Species~.,data = iris)
plot(model)
table(predict(model),iris$Species)##
## setosa versicolor virginica
## setosa 50 0 0
## versicolor 0 49 5
## virginica 0 1 45library(rpart) model2=rpart(Species~.,data = iris) fancyRpartPlot(model2)
library(randomForest)## randomForest 4.6-12## Type rfNews() to see new features/changes/bug fixes.model3=randomForest(Species~.,data = iris)
table(predict(model3),iris$Species)##
## setosa versicolor virginica
## setosa 50 0 0
## versicolor 0 47 4
## virginica 0 3 46from https://github.com/decisionstats/pythonfordatascience/blob/master/2%2BClustering%2B-K%2BMeans.ipynb
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import KMeans
import sklearn.metrics as sm
import pandas as pd
import numpy as np
wine=pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data",header=None)
wine.head()
wine.columns=['winetype','Alcohol','Malic acid','Ash','Alcalinity of ash','Magnesium','Total phenols','Flavanoids','Nonflavanoid phenols','Proanthocyanins','Color intensity','Hue','OD280/OD315 of diluted wines','Proline']
wine.head()
wine.info()
wine.describe()
pd.value_counts(wine['winetype'])
x=wine.ix[:,1:14]
y=wine.ix[:,:1]
x.columns
y.columns
x.head()
y.head()
# K Means Cluster
model = KMeans(n_clusters=3)
model.fit(x)
model.labels_
pd.value_counts(model.labels_)
pd.value_counts(y['winetype'])
# We convert all the 1s to 0s and 0s to 1s.
predY = np.choose(model.labels_, [2, 1, 3]).astype(np.int64)
pd.value_counts(y['winetype'])
pd.value_counts(model.labels_)
pd.value_counts(predY)
# Performance Metrics
sm.accuracy_score(y, predY)
# Confusion Matrix
sm.confusion_matrix(y, predY)
from ggplot import *
%matplotlib inline
p = ggplot(aes(x='Alcohol', y='Ash',color="winetype"), data=wine)
p + geom_point()
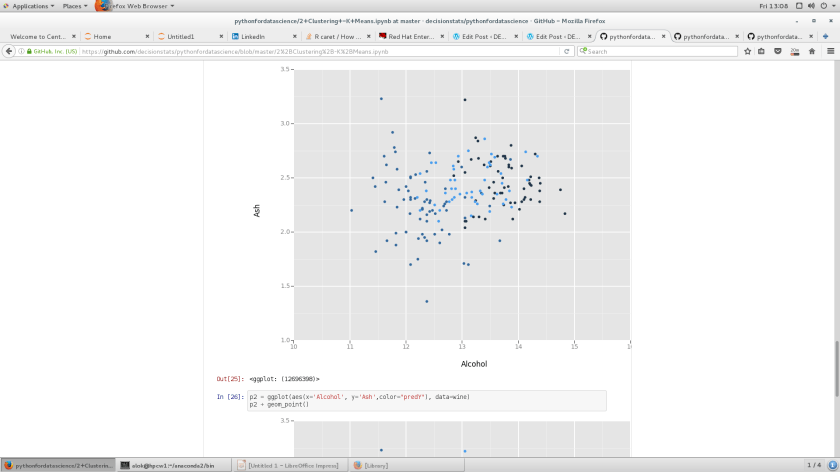
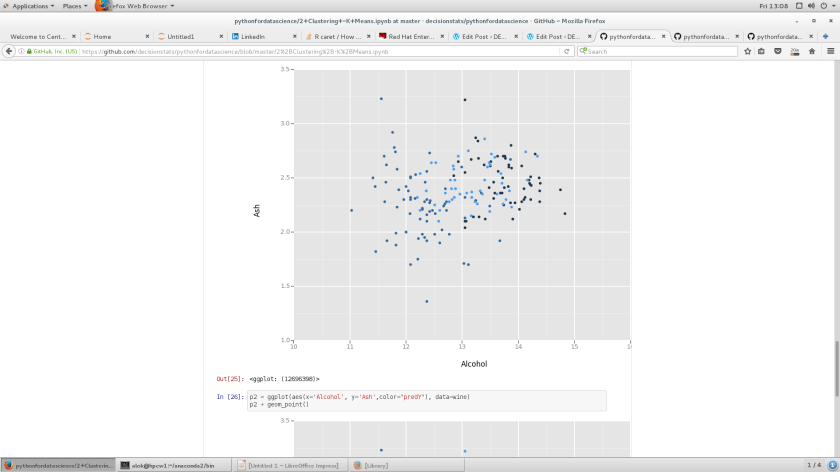
p2 = ggplot(aes(x='Alcohol', y='Ash',color="predY"), data=wine)
p2 + geom_point()
import psycopg2
import pandas as pd
import sqlalchemy as sa
import time
import seaborn as sns
import re
!pip install psycopg2
parameters = {
'username': 'postgres',
'password': 'root',
'server': 'localhost',
'database': 'datascience'
}
connection= 'postgresql://{username}:{password}@{server}:5432/{database}'.format(**parameters)
print (connection)
engine = sa.create_engine(connection, encoding="utf-8")
insp = sa.inspect(engine)
db_list = insp.get_schema_names()
print(db_list)
print(insp)
engine.table_names()
data3= pd.read_sql_query('select * from "sales77" limit 10',con=engine)
print(data3)

