From-
http://www.dataminingblog.com/data-mining-research-interview-ajay-ohri/
Here is the winner of the Data Mining Research People Award 2010: Ajay Ohri! Thanks to Ajay for giving some time to answer Data Mining Research questions. And all the best to his blog, Decision Stat!
Data Mining Research (DMR): Could you please introduce yourself to the readers of Data Mining Research?
Ajay Ohri (AO): I am a business consultant and writer based out of Delhi- India. I have been working in and around the field of business analytics since 2004, and have worked with some very good and big companies primarily in financial analytics and outsourced analytics. Since 2007, I have been writing my blog at http://decisionstats.com which now has almost 10,000 views monthly.
All in all, I wrote about data, and my hobby is also writing (poetry). Both my hobby and my profession stem from my education ( a masters in business, and a bachelors in mechanical engineering).
My research interests in data mining are interfaces (simpler interfaces to enable better data mining), education (making data mining less complex and accessible to more people and students), and time series and regression (specifically ARIMAX)
In business my research interests software marketing strategies (open source, Software as a service, advertising supported versus traditional licensing) and creation of technology and entrepreneurial hubs (like Palo Alto and Research Triangle, or Bangalore India).
DMR: I know you have worked with both SAS and R. Could you give your opinion about these two data mining tools?
AO: As per my understanding, SAS stands for SAS language, SAS Institute and SAS software platform. The terms are interchangeably used by people in industry and academia- but there have been some branding issues on this.
I have not worked much with SAS Enterprise Miner , probably because I could not afford it as business consultant, and organizations I worked with did not have a budget for Enterprise Miner.
I have worked alone and in teams with Base SAS, SAS Stat, SAS Access, and SAS ETS- and JMP. Also I worked with SAS BI but as a user to extract information.
You could say my use of SAS platform was mostly in predictive analytics and reporting, but I have a couple of projects under my belt for knowledge discovery and data mining, and pattern analysis. Again some of my SAS experience is a bit dated for almost 1 year ago.
I really like specific parts of SAS platform – as in the interface design of JMP (which is better than Enterprise Guide or Base SAS ) -and Proc Sort in Base SAS- I guess sequential processing of data makes SAS way faster- though with computing evolving from Desktops/Servers to even cheaper time shared cloud computers- I am not sure how long Base SAS and SAS Stat can hold this unique selling proposition.
I dislike the clutter in SAS Stat output, it confuses me with too much information, and I dislike shoddy graphics in the rendering output of graphical engine of SAS. Its shoddy coding work in SAS/Graph and if JMP can give better graphics why is legacy source code preventing SAS platform from doing a better job of it.
I sometimes think the best part of SAS is actually code written by Goodnight and Sall in 1970’s , the latest procs don’t impress me much.
SAS as a company is something I admire especially for its way of treating employees globally- but it is strange to see the rest of tech industry not following it. Also I don’t like over aggression and the SAS versus Rest of the Analytics /Data Mining World mentality that I sometimes pick up when I deal with industry thought leaders.
I think making SAS Enterprise Miner, JMP, and Base SAS in a completely new web interface priced at per hour rates is my wishlist but I guess I am a bit sentimental here- most data miners I know from early 2000’s did start with SAS as their first bread earning software. Also I think SAS needs to be better priced in Business Intelligence- it seems quite cheap in BI compared to Cognos/IBM but expensive in analytical licensing.
If you are a new stats or business student, chances are – you may know much more R than SAS today. The shift in education at least has been very rapid, and I guess R is also more of a platform than a analytics or data mining software.
I like a lot of things in R- from graphics, to better data mining packages, modular design of software, but above all I like the can do kick ass spirit of R community. Lots of young people collaborating with lots of young to old professors, and the energy is infectious. Everybody is a CEO in R ’s world. Latest data mining algols will probably start in R, published in journals.
Which is better for data mining SAS or R? It depends on your data and your deadline. The golden rule of management and business is -it depends.
Also I have worked with a lot of KXEN, SQL, SPSS.
DMR: Can you tell us more about Decision Stats? You have a traffic of 120′000 for 2010. How did you reach such a success?
AO: I don’t think 120,000 is a success. Its not a failure. It just happened- the more I wrote, the more people read.In 2007-2008 I used to obsess over traffic. I tried SEO, comments, back linking, and I did some black hat experimental stuff. Some of it worked- some didn’t.
In the end, I started asking questions and interviewing people. To my surprise, senior management is almost always more candid , frank and honest about their views while middle managers, public relations, marketing folks can be defensive.
Social Media helped a bit- Twitter, Linkedin, Facebook really helped my network of friends who I suppose acted as informal ambassadors to spread the word.
Again I was constrained by necessity than choices- my middle class finances ( I also had a baby son in 2007-my current laptop still has some broken keys  – by my inability to afford traveling to conferences, and my location Delhi isn’t really a tech hub.
– by my inability to afford traveling to conferences, and my location Delhi isn’t really a tech hub.
The more questions I asked around the internet, the more people responded, and I wrote it all down.
I guess I just was lucky to meet a lot of nice people on the internet who took time to mentor and educate me.
I tried building other websites but didn’t succeed so i guess I really don’t know. I am not a smart coder, not very clever at writing but I do try to be honest.
Basic economics says pricing is proportional to demand and inversely proportional to supply. Honest and candid opinions have infinite demand and an uncertain supply.
DMR: There is a rumor about a R book you plan to publish in 2011 Can you confirm the rumor and tell us more?
AO: I just signed a contract with Springer for ” R for Business Analytics”. R is a great software, and lots of books for statistically trained people, but I felt like writing a book for the MBAs and existing analytics users- on how to easily transition to R for Analytics.
Like any language there are tricks and tweaks in R, and with a focus on code editors, IDE, GUI, web interfaces, R’s famous learning curve can be bent a bit.
Making analytics beautiful, and simpler to use is always a passion for me. With 3000 packages, R can be used for a lot more things and a lot more simply than is commonly understood.
The target audience however is business analysts- or people working in corporate environments.
Brief Bio-
Ajay Ohri has been working in the field of analytics since 2004 , when it was a still nascent emerging Industries in India. He has worked with the top two Indian outsourcers listed on NYSE,and with Citigroup on cross sell analytics where he helped sell an extra 50000 credit cards by cross sell analytics .He was one of the very first independent data mining consultants in India working on analytics products and domestic Indian market analytics .He regularly writes on analytics topics on his web site www.decisionstats.com and is currently working on open source analytical tools like R besides analytical software like SPSS and SAS.
28.635308
77.224960

 Create
Create Choose New Infographic or New Chart?
Choose New Infographic or New Chart?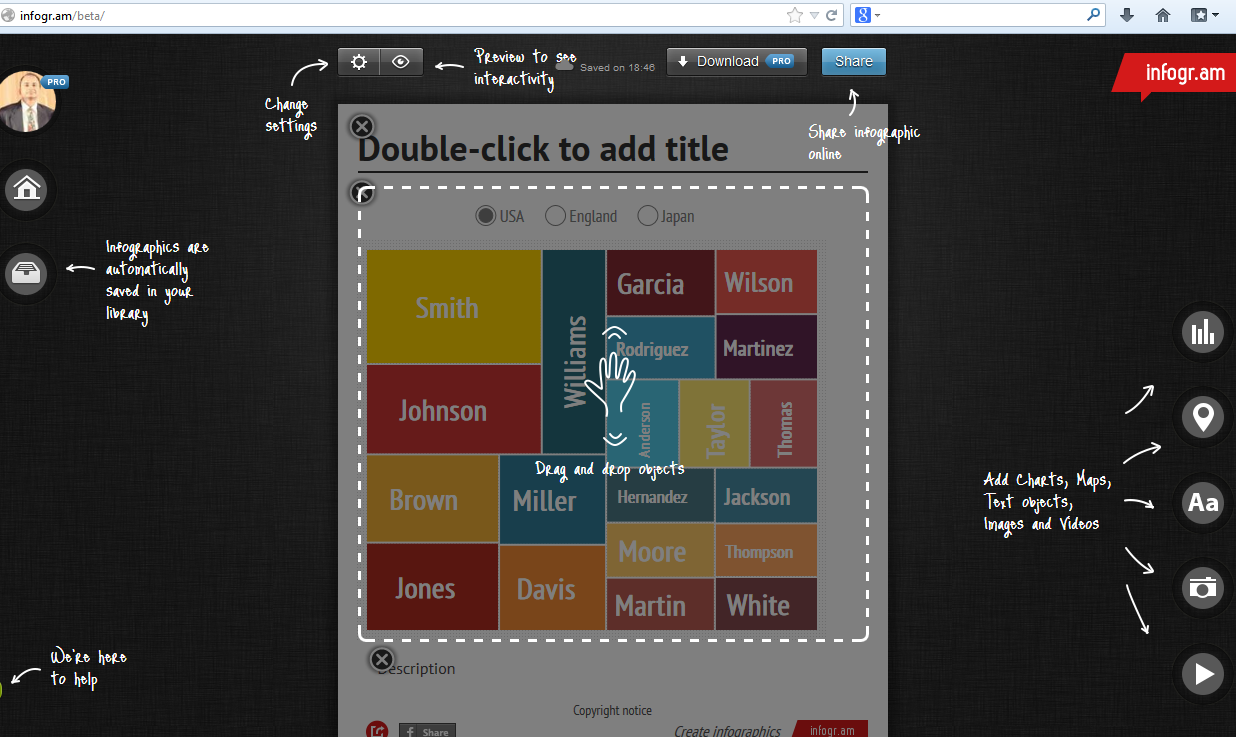 Create using options-you can edit the table, figures, text, colors etc
Create using options-you can edit the table, figures, text, colors etc