Here is an interview with Tobias Verbeke, Managing Director of Open Analytics (
http://www.openanalytics.eu/). Open Analytics is doing cutting edge work with R in the enterprise software space.
Ajay- Describe your career journey including your involvement with Open Source and R. What things enticed you to try R?
Tobias- I discovered the free software foundation while still at university and spent wonderful evenings configuring my GNU/Linux system and reading RMS essays. For the statistics classes proprietary software was proposed and that was obviously not an option, so I started tackling all problems using R which was at the time (around 2000) still an underdog together with pspp (a command-line SPSS clone) and xlispstat. From that moment on, I decided that R was the hammer and all problems to be solved were nails 😉 In my early career I worked as a statistician / data miner for a general consulting company which gave me the opportunity to bring R into Fortune 500 companies and learn what was needed to support its use in an enterprise context. In 2008 I founded Open Analytics to turn these lessons into practice and we started building tools to support the data analysis process using R. The first big project was Architect, which started as an eclipse-based R IDE, but more and more evolves into an IDE for data science more generally. In parallel we started working on infrastructure to automate R-based analyses and to plug R (and therefore statistical logic) into larger business processes and soon we had a tool suite to cover the needs of industry.
Ajay- What is RSB all about- what needs does it satisfy- who can use it ?
Tobias– RSB stands for the R Service Bus and is communication middleware and a work manager for R jobs. It allows to trigger and receive results from R jobs using a plethora of protocols such as RESTful web services, e-mail protocols, sftp, folder polling etc. The idea is to enable people to push a button (or software to make a request) and have them receive automated R based analysis results or reports for their data.
Ajay- What is your vision and what have been the challenges and learning so far in the project
Tobias– RSB started when automating toxicological analyses in pharmaceutical industry in collaboration with Philippe Lamote. Together with David Dossot, an exceptional software architect in Vancouver, we decided to cleanly separate concerns, namely to separate the integration layer (RSB) from the statistical layer (R) and, likewise, from the application layer. As a result any arbitrary R code can be run via RSB and any client application can interact with RSB as long as it can talk one of the many supported protocols. This fundamental design principle makes us different from alternative solutions where statistical logic and integration logic are always somehow interwoven, which results in maintenance and integration headaches. One of the challenges has been to keep focus on the core task of automating statistical analyses and not deviating into features that would turn RSB into a tool for interaction with an R session, which deserves an entirely different approach. 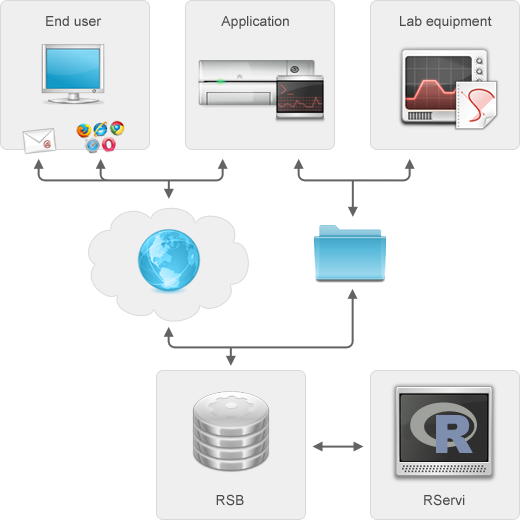
Ajay- Computing seems to be moving to an heterogeneous cloud , server and desktop model. What do you think about the R and Cloud Computing- current and future
Tobias– From a freedom perspective, cloud computing and the SaaS model is often a step backwards, but in our own practice we obviously follow our customers’ needs and offer RSB hosting from our data centers as well. Also, our other products e.g. the R IDE Architect are ready for the cloud and use on servers via Architect Server. As far as R itself concerns in relation to cloud computing, I foresee its use to increase. At Open Analytics we see an increasing demand for R-based statistical engines that power web applications living in the cloud.
Ajay- You recently released RSB version 6. What are all the new features. What is the planned roadmap going forward
Tobias– RSB 6.0 is all about large-scale production environments and strong security. It kicked off on a project where RSB was responsible for spitting 8500 predictions per second. Such large-scale production deployments of RSB motivated the development of a series of features. First of all RSB was made lightning fast: we achieved a full round trip from REST call to prediction in 7 ms on the mentioned use case. In order to allow for high throughput, RSB also gained a synchronous API (RSB 5.0 had an asynchronous API only). Another new feature is the availability of client-side connection pooling to the pool manager of R processes that are read to serve RSB. Besides speed, this type of production environments also need monitoring and resilience in case of issues. For the monitoring, we made sure that everything is in place for monitoring and remotely querying not only the RSB application itself, but also the pool of R processes managed by RServi.
(Note from Ajay- RJ is an open source library providing tools and interfaces to integrate R in Java applications. RJ project also provides a pool for R engines, easy to setup and manage by a web-interface or JMX. One or multiple client can borrow the R engines (called RServi) see http://www.walware.de/it/rj/ and https://github.com/walware/rj-servi)
Also, we now allow to define node validation strategies to be able to check that R nodes are still functioning properly. If not, the nodes are killed and new nodes are started and added to the pool. In terms of security, we are now able to cover a very wide spectrum of authentication and authorization. We have machines up and running using openid, basic http authentication, LDAP, SSL client certificates etc. to serve everyone from the individual user who is happy with openid authentication for his RSB app to large investment banks who have very strong security requirements. The next step is to provide tighter integration with Architect, such that people can release new RSB applications without leaving the IDE.
Ajay- How does the startup ecosystem in Europe compare with say the SF Bay Area, What are some of the good things and not so great things
Tobias– I do not feel qualified to answer such a question, since I founded a single company in Antwerp, Belgium. That being said, Belgium is great! 🙂
Ajay- How can we popularize STEM education using MooCs , training etc
Tobias– Free software. Free as in beer and as in free speech!
Ajay- Describe the open source ecosystem in general and R ecosystem in particular for Europe. How does it compare with other locations in your opinion
Tobias– Open source is probably a global ecosystem and crosses oceans very easily. Dries Buytaert started off Drupal in Belgium and now operates from the US interacting with a global community. From a business perspective, there are as many open source models as there are open source companies. I noticed that the major US R companies (Revolution Analytics and RStudio) cherished the open source philosophy initially, but drifted both into models combining open source and proprietary components. At Open Analytics, there are only open source products and enterprise customers have access to exactly the same functionality as a student may have in a developing country. That being said, I don’t believe this is a matter of geography, but has to do more with the origins and different strategies of the companies.
Ajay- What do you do for work life balance and de stressing when not shipping code.
Tobias- In a previous life the athletics track helped keeping hands off the keyboard. Currently, my children find very effective ways to achieve similar goals
About-
OpenAnalytics is a consulting company specialized in statistical computing using open technologies. You can read more on it at http://www.openanalytics.eu