Here is an interview with Prof Rob J Hyndman who has created many time series forecasting methods and authored books as well as R packages on the same.

Ajay -Describe your journey from being a student of science to a Professor. What were some key turning points along that journey?
Rob- I started a science honours degree at the University of Melbourne in 1985. By the end of 1985 I found myself simultaneously working as a statistical consultant (having completed all of one year of statistics courses!). For the next three years I studied mathematics, statistics and computer science at university, and tried to learn whatever I needed to in order to help my growing group of clients. Often we would cover things in classes that I’d already taught myself through my consulting work. That really set the trend for the rest of my career. I’ve always been an academic on the one hand, and a statistical consultant on the other. The consulting work has led me to learn a lot of things that I would not otherwise have come across, and has also encouraged me to focus on research problems that are of direct relevance to the clients I work with.
I never set out to be an academic. In fact, I thought that I would get a job in the business world as soon as I finished my degree. But once I completed the degree, I was offered a position as a statistical consultant within the University of Melbourne, helping researchers in various disciplines and doing some commercial work. After a year, I was getting bored doing only consulting, and I thought it would be interesting to do a PhD. I was lucky enough to be offered a generous scholarship which meant I was paid more to study than to continue working.
Again, I thought that I would probably go and get a job in the business world after I finished my PhD. But I finished it early and my scholarship was going to be cut off once I submitted my thesis. So instead, I offered to teach classes for free at the university and delayed submitting my thesis until the scholarship period ran out. That turned out to be a smart move because the university saw that I was a good teacher, and offered me a lecturing position starting immediately I submitted my thesis. So I sort of fell into an academic career.
I’ve kept up the consulting work part-time because it is interesting, and it gives me a little extra money. But I’ve also stayed an academic because I love the freedom to be able to work on anything that takes my fancy.
Ajay- Describe your upcoming book on Forecasting.
Rob- My first textbook on forecasting (with Makridakis and Wheelwright) was written a few years after I finished my PhD. It has been very popular, but it costs a lot of money (about $140 on Amazon). I estimate that I get about $1 for every book sold. The rest goes to the publisher (Wiley) and all they do is print, market and distribute it. I even typeset the whole thing myself and they print directly from the files I provided. It is now about 15 years since the book was written and it badly needs updating. I had a choice of writing a new edition with Wiley or doing something completely new. I decided to do a new one, largely because I didn’t want a publisher to make a lot of money out of students using my hard work.
It seems to me that students try to avoid buying textbooks and will search around looking for suitable online material instead. Often the online material is of very low quality and contains many errors.
As I wasn’t making much money on my textbook, and the facilities now exist to make online publishing very easy, I decided to try a publishing experiment. So my new textbook will be online and completely free. So far it is about 2/3 completed and is available at
http://otexts.com/fpp/. I am hoping that my co-author (George Athanasopoulos) and I will finish it off before the end of 2012.
The book is intended to provide a comprehensive introduction to forecasting methods. We don’t attempt to discuss the theory much, but provide enough information for people to use the methods in practice. It is tied to the forecast package in R, and we provide code to show how to use the various forecasting methods.
The idea of online textbooks makes a lot of sense. They are continuously updated so if we find a mistake we fix it immediately. Also, we can add new sections, or update parts of the book, as required rather than waiting for a new edition to come out. We can also add richer content including video, dynamic graphics, etc.
For readers that want a print edition, we will be aiming to produce a print version of the book every year (available via Amazon).
I like the idea so much I’m trying to set up a new publishing platform (
otexts.com) to enable other authors to do the same sort of thing. It is taking longer than I would like to make that happen, but probably next year we should have something ready for other authors to use.
Ajay- How can we make textbooks cheaper for students as well as compensate authors fairly
With
otexts.com, we will compensate authors in two ways. First, the print versions of a book will be sold (although at a vastly cheaper rate than other commercial publishers). The royalties on print sales will be split 50/50 with the authors. Second, we plan to have some features of each book available for subscription only (e.g., solutions to exercises, some multimedia content, etc.). Again, the subscription fees will be split 50/50 with the authors.
Ajay- Suppose a person who used to use forecasting software from another company decides to switch to R. How easy and lucid do you think the current documentation on R website for business analytics practitioners such as these – in the corporate world.
Rob- The documentation on the R website is not very good for newcomers, but there are a lot of other R resources now available. One of the best introductions is Matloff’s “The Art of R Programming”. Provided someone has done some programming before (e.g., VBA, python or java), learning R is a breeze. The people who have trouble are those who have only ever used menu interfaces such as Excel. Then they are not only learning R, but learning to think about computing in a different way from what they are used to, and that can be tricky. However, it is well worth it. Once you know how to code, you can do so much more. I wish some basic programming was part of every business and statistics degree.
If you are working in a particular area, then it is often best to find a book that uses R in that discipline. For example, if you want to do forecasting, you can use my book (
otexts.com/fpp/). Or if you are using R for data visualization, get hold of Hadley Wickham’s ggplot2 book.
Ajay- In a long and storied career- What is the best forecast you ever made ? and the worst?
Rob- Actually, my best work is not so much in making forecasts as in developing new forecasting methodology. I’m very proud of my forecasting models for electricity demand which are now used for all long-term planning of electricity capacity in Australia (see
http://robjhyndman.com/papers/peak-electricity-demand/ for the details). Also, my methods for population forecasting (
http://robjhyndman.com/papers/stochastic-population-forecasts/ ) are pretty good (in my opinion!). These methods are now used by some national governments (but not Australia!) for their official population forecasts.
Of course, I’ve made some bad forecasts, but usually when I’ve tried to do more than is reasonable given the available data. One of my earliest consulting jobs involved forecasting the sales for a large car manufacturer. They wanted forecasts for the next fifteen years using less than ten years of historical data. I should have refused as it is unreasonable to forecast that far ahead using so little data. But I was young and naive and wanted the work. So I did the forecasts, and they were clearly outside the company’s (reasonable) expectations, and they then refused to pay me. Lesson learned. It’s better to refuse work than do it poorly.
Probably the biggest impact I’ve had is in helping the Australian government forecast the national health budget. In 2001 and 2002, they had underestimated health expenditure by nearly $1 billion in each year which is a lot of money to have to find, even for a national government. I was invited to assist them in developing a new forecasting method, which I did. The new method has forecast errors of the order of plus or minus $50 million which is much more manageable. The method I developed for them was the basis of the ETS models discussed in my 2008 book on exponential smoothing (www.exponentialsmoothing.net)
. And now anyone can use the method with the ets() function in the forecast package for R.
About-
Rob J Hyndman is Professor of Statistics in the
Department of Econometrics and Business Statistics at
Monash University and Director of the Monash University Business & Economic Forecasting Unit. He is also Editor-in-Chief of the
International Journal of Forecasting and a Director of the
International Institute of Forecasters. Rob is the author of over 100 research papers in statistical science. In 2007, he received the Moran medal from the Australian Academy of Science for his contributions to statistical research, especially in the area of statistical forecasting. For 25 years, Rob has maintained an active consulting practice, assisting hundreds of companies and organizations. His recent consulting work has involved forecasting electricity demand, tourism demand, the Australian government health budget and case volume at a US call centre.

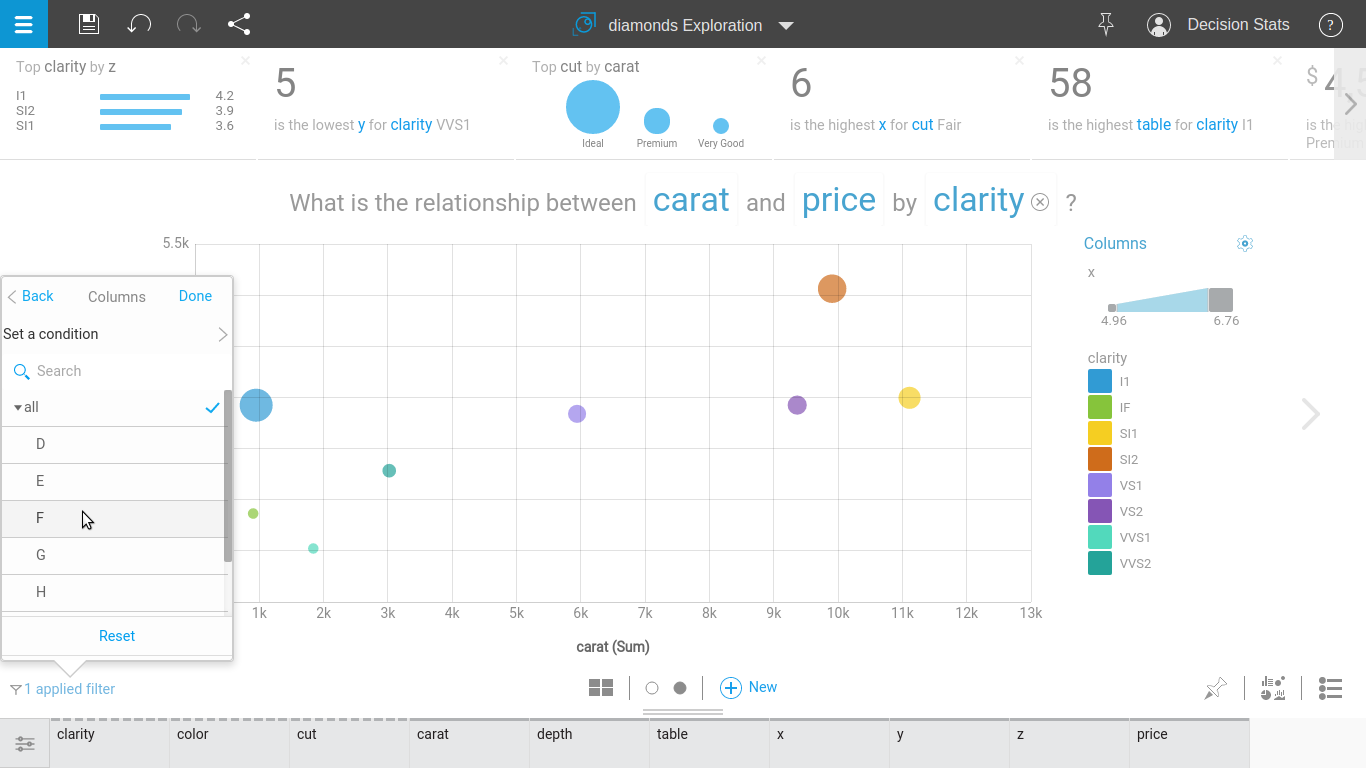
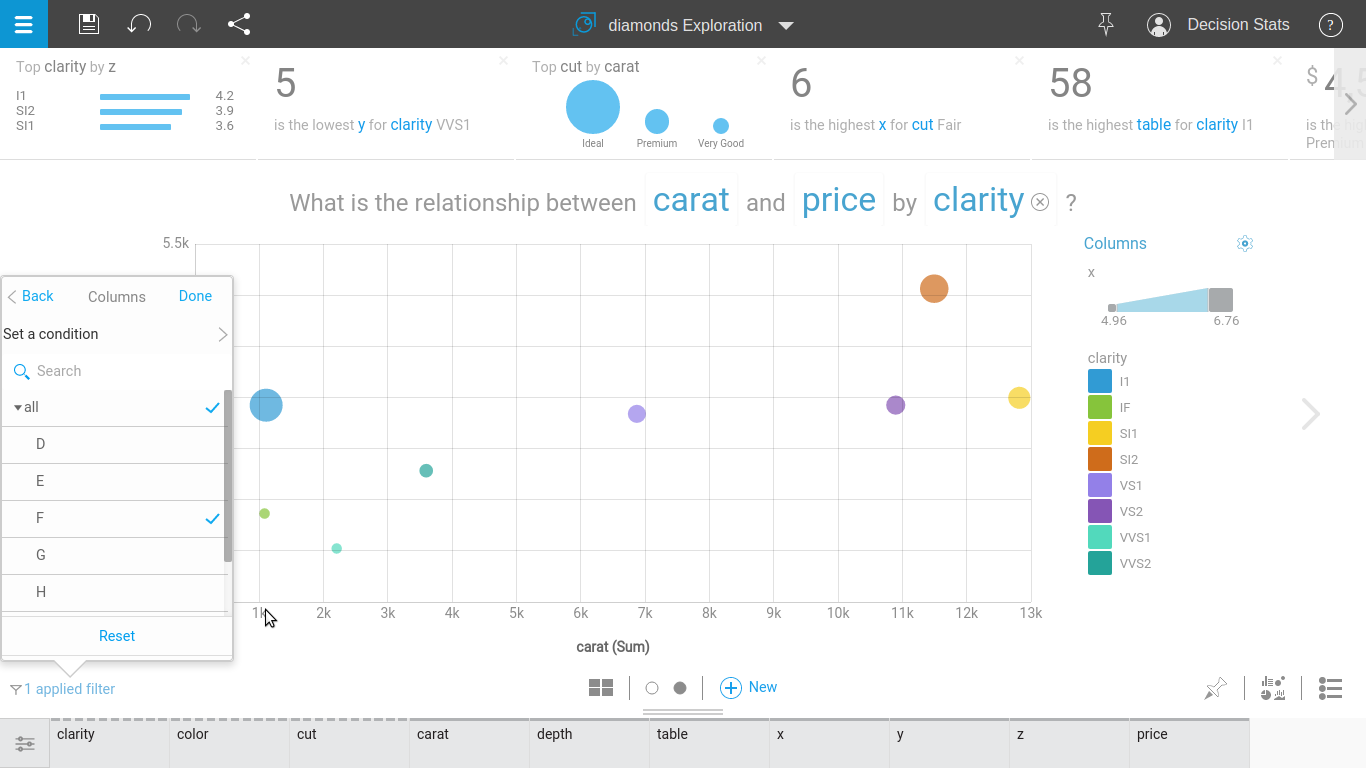
 Step 2
Step 2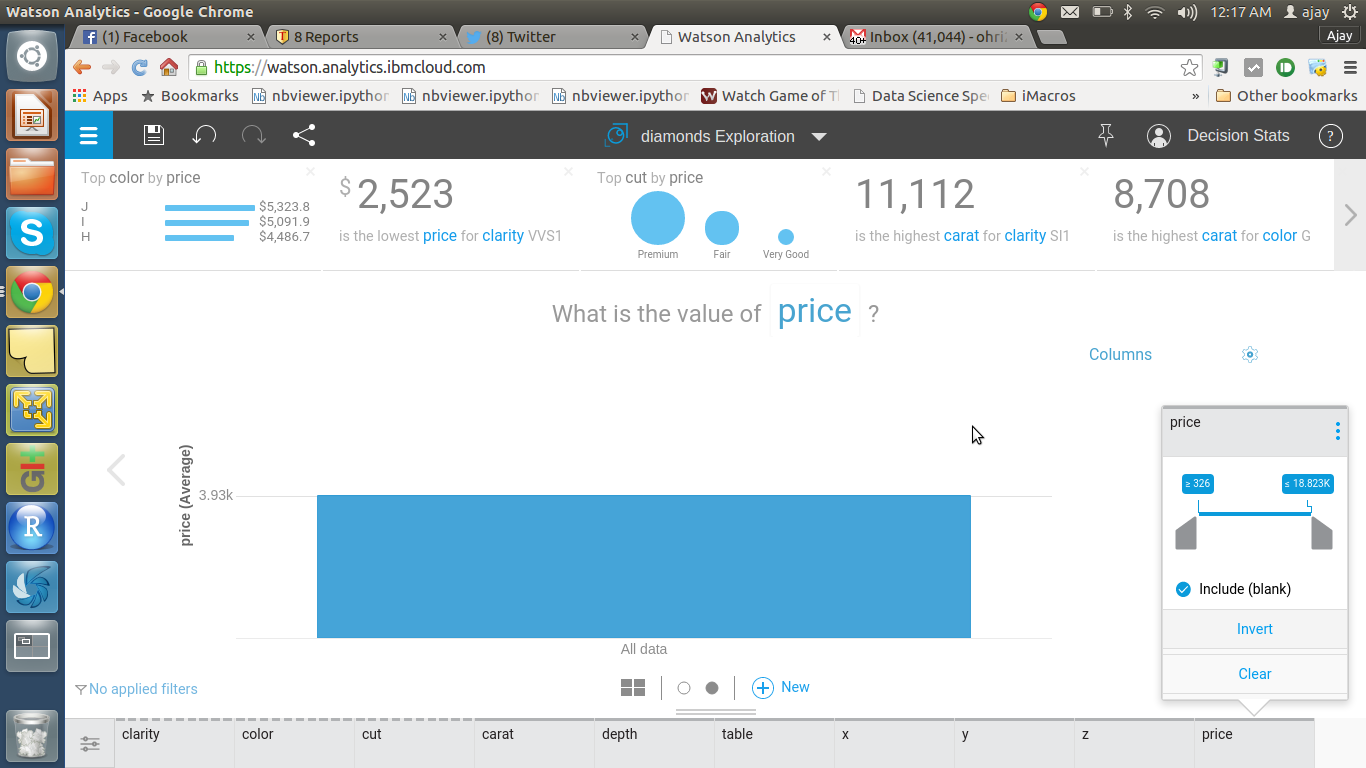
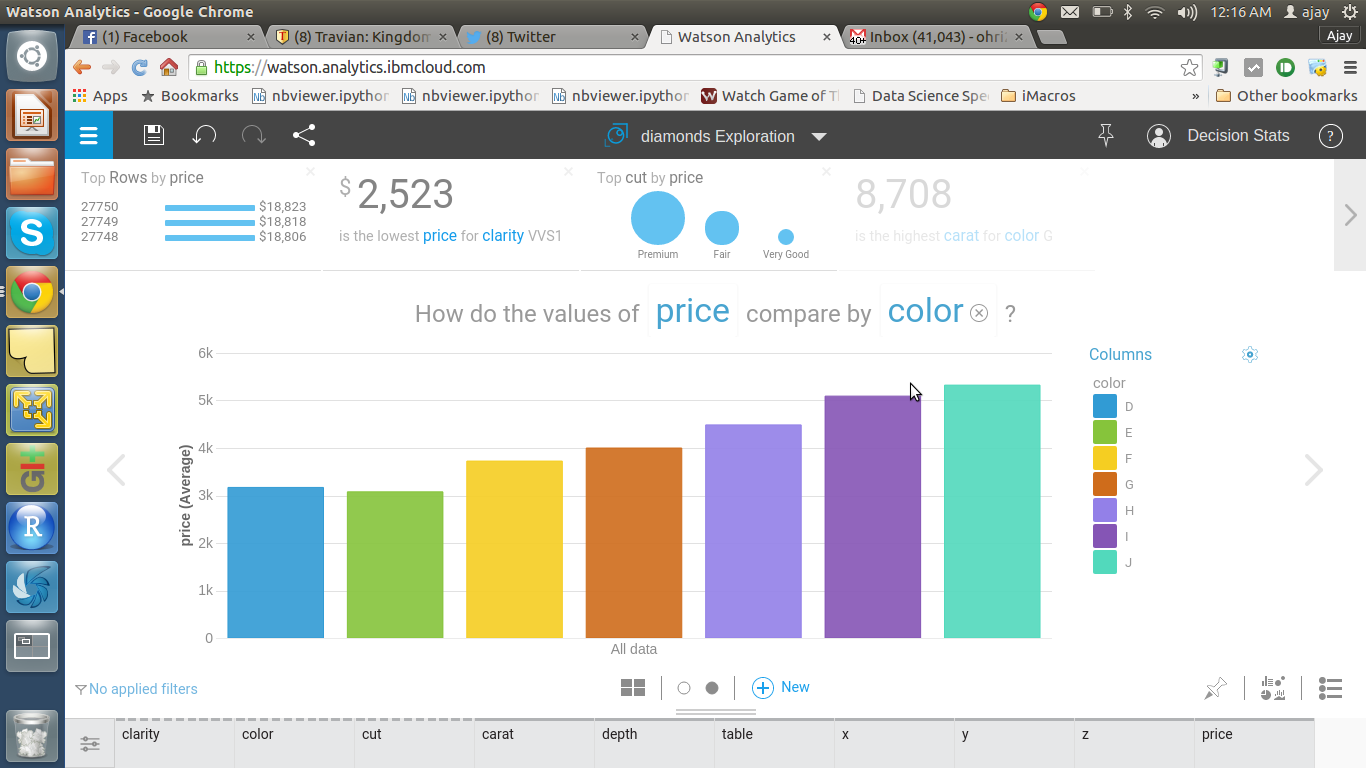
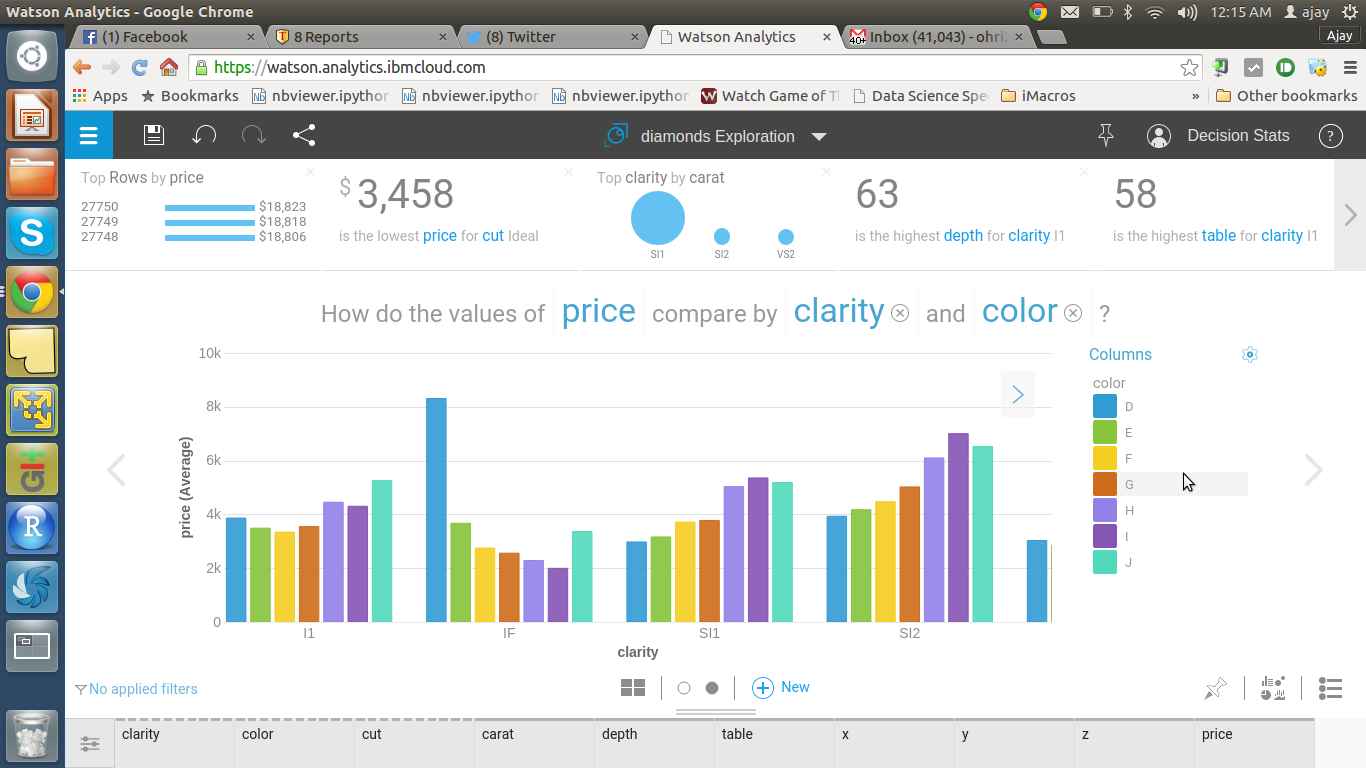
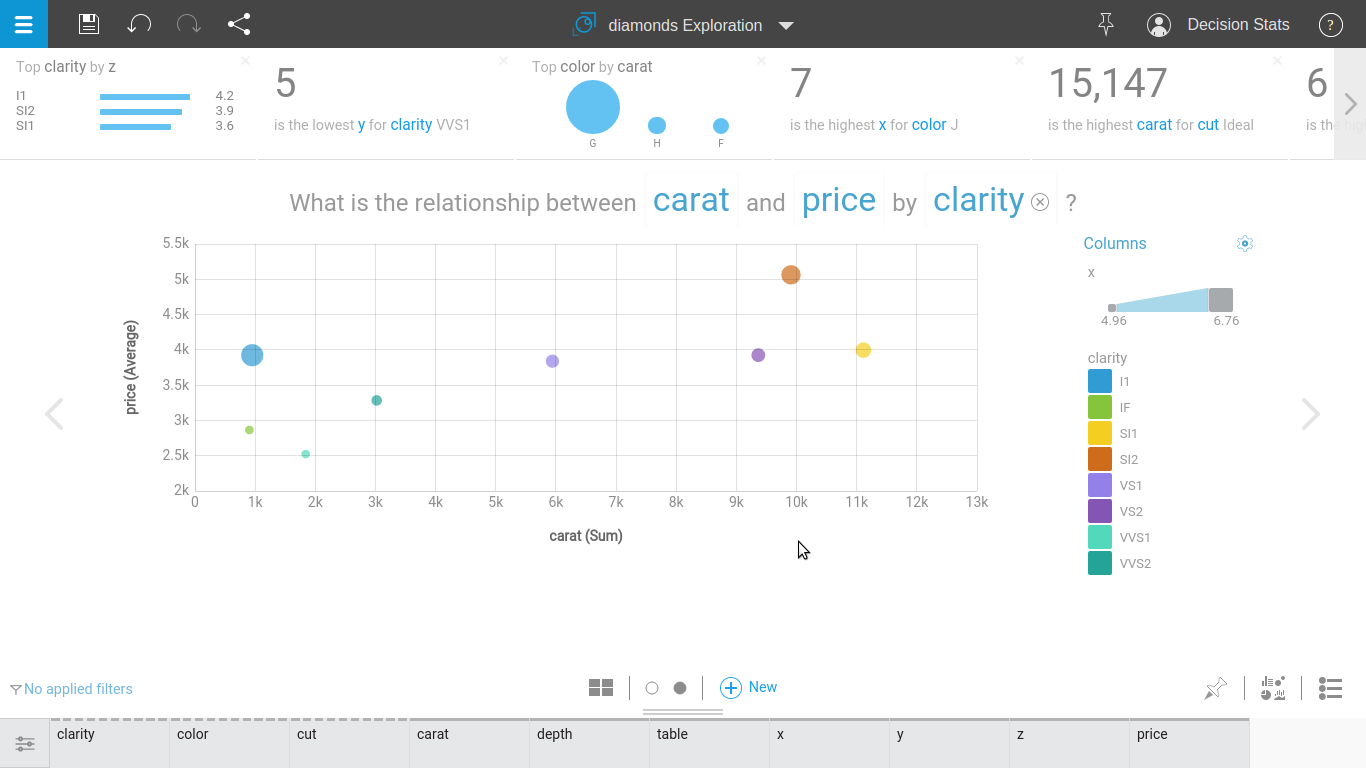 Step 3
Step 3