from http://www.sas.com/events/analytics/us/index.html
Analytics 2012 Conference
SAS and more than 1,000 analytics experts gather at

Caesars Palace
Analytics 2012 Conference Details
Pre-Conference Workshops – Oct 7
Conference – Oct 8-9
Post-Conference Training – Oct 10-12
Caesars Palace, Las Vegas
Keynote Speakers
The following are confirmed keynote speakers for Analytics 2012.  Since he co-founded SAS in 1976, Jim Goodnight has served as the company’s Chief Executive Officer.
Since he co-founded SAS in 1976, Jim Goodnight has served as the company’s Chief Executive Officer.
 Dr. William Hakes is the CEO and co-founder of Link Analytics, an analytical technology company focused on mobile, energy and government verticals.
Dr. William Hakes is the CEO and co-founder of Link Analytics, an analytical technology company focused on mobile, energy and government verticals.
 Tim Rey has written over 100 internal papers, published 21 external papers, and delivered numerous keynote presentations and technical talks at various quantitative methods forums. Recently he has co-chaired both forecasting and data mining conferences. He is currently in the process of co-writing a book, Applied Data Mining for Forecasting.
Tim Rey has written over 100 internal papers, published 21 external papers, and delivered numerous keynote presentations and technical talks at various quantitative methods forums. Recently he has co-chaired both forecasting and data mining conferences. He is currently in the process of co-writing a book, Applied Data Mining for Forecasting.
http://www.sas.com/events/analytics/us/train.html
Pre-Conference
Plan to come to Analytics 2012 a day early and participate in one of the pre-conference workshops or take a SAS Certification exam. Prices for all of the preconference workshops, except for SAS Sentiment Analysis Studio: Introduction to Building Models and the Business Analytics Consulting Workshops, are included in the conference package pricing. You will be prompted to select your pre-conference training options when you register.
Sunday Morning Workshop
SAS Sentiment Analysis Studio: Introduction to Building Models
This course provides an introduction to SAS Sentiment Analysis Studio. It is designed for system designers, developers, analytical consultants and managers who want to understand techniques and approaches for identifying sentiment in textual documents.
View outline
Sunday, Oct. 7, 8:30a.m.-12p.m. – $250
Sunday Afternoon Workshops
Business Analytics Consulting Workshops
This workshop is designed for the analyst, statistician, or executive who wants to discuss best-practice approaches to solving specific business problems, in the context of analytics. The two-hour workshop will be customized to discuss your specific analytical needs and will be designed as a one-on-one session for you, including up to five individuals within your company sharing your analytical goal. This workshop is specifically geared for an expert tasked with solving a critical business problem who needs consultation for developing the analytical approach required. The workshop can be customized to meet your needs, from a deep-dive into modeling methods to a strategic plan for analytic initiatives. In addition to the two hours at the conference location, this workshop includes some advanced consulting time over the phone, making it a valuable investment at a bargain price.
View outline
Sunday, Oct. 7; 1-3 p.m. or 3:30-5:30 p.m. – $200
Demand-Driven Forecasting: Sensing Demand Signals, Shaping and Predicting Demand
This half-day lecture teaches students how to integrate demand-driven forecasting into the consensus forecasting process and how to make the current demand forecasting process more demand-driven.
View outline
Sunday, Oct. 7; 1-5 p.m.
Forecast Value Added Analysis
Forecast Value Added (FVA) is the change in a forecasting performance metric (such as MAPE or bias) that can be attributed to a particular step or participant in the forecasting process. FVA analysis is used to identify those process activities that are failing to make the forecast any better (or might even be making it worse). This course provides step-by-step guidelines for conducting FVA analysis – to identify and eliminate the waste, inefficiency, and worst practices from your forecasting process. The result can be better forecasts, with fewer resources and less management time spent on forecasting.
View outline
Sunday, Oct. 7; 1-5 p.m.
SAS Enterprise Content Categorization: An Introduction
This course gives an introduction to methods of unstructured data analysis, document classification and document content identification. The course also uses examples as the basis for constructing parse expressions and resulting entities.
View outline
Sunday, Oct. 7; 1-5 p.m.
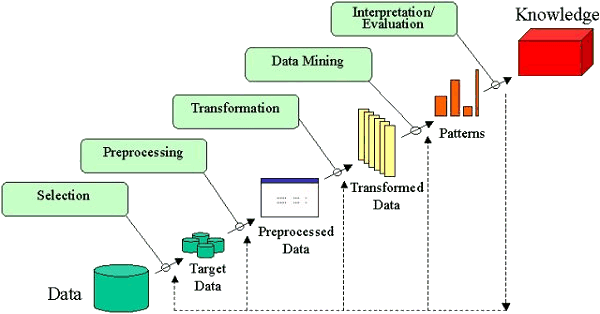
Introduction to Data Mining and SAS Enterprise Miner
This course serves as an introduction to data mining and SAS Enterprise Miner for Desktop software. It is designed for data analysts and qualitative experts as well as those with less of a technical background who want a general understanding of data mining.
View outline
Sunday, Oct. 7, 1-5 p.m.
Modeling Trend, Cycles, and Seasonality in Time Series Data Using PROC UCM
This half-day lecture teaches students how to model, interpret, and predict time series data using UCMs. The UCM procedure analyzes and forecasts equally spaced univariate time series data using the unobserved components models (UCM). This course is designed for business analysts who want to analyze time series data to uncover patterns such as trend, seasonal effects, and cycles using the latest techniques.
View outline
Sunday, Oct. 7, 1-5 p.m.
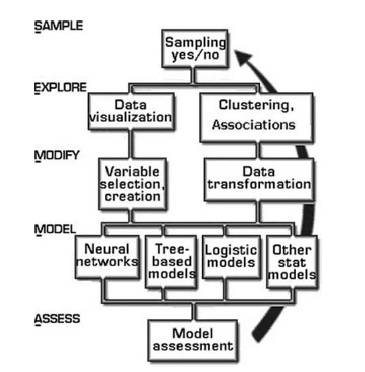
SAS Rapid Predictive Modeler
This seminar will provide a brief introduction to the use of SAS Enterprise Guide for graphical and data analysis. However, the focus will be on using SAS Enterprise Guide and SAS Enterprise Miner along with the Rapid Predictive Modeling component to build predictive models. Predictive modeling will be introduced using the SEMMA process developed with the introduction of SAS Enterprise Miner. Several examples will be used to illustrate the use of the Rapid Predictive Modeling component, and interpretations of the model results will be provided.
View outline
Sunday, Oct. 7, 1-5 p.m