Another xing bang API from the boyz in Mountain View. (entry by invite only) But it is free and you can test your stuff on a MySQL db =10 GB
Database as a service ? (Maybe)— while Amazon was building fires (and Fire)
—————————————————————–
https://code.google.com/apis/sql/index.html

What is Google Cloud SQL?
Google Cloud SQL is a web service that provides a highly available, fully-managed, hosted SQL storage solution for your App Engine applications.
What are the benefits of using Google Cloud SQL?
You can access a familiar, highly available SQL database from your App Engine applications, without having to worry about provisioning, management, and integration with other Google services.
How much does Google Cloud SQL cost?
We will not be billing for this service in 2011. We will give you at least 30 days’ advance notice before we begin billing in the future. Other services such as Google App Engine, Google Cloud Storage etc. that you use with Google Cloud SQL may have their own payment terms, and you need to pay for them. Please consult their documentation for details.
Currently you are limited to the three instance sizes. What if I need to store more data or need better performance?
In the Limited Preview period, we only have three sizes available. If you have specific needs, we would like to hear from you on our google-cloud-sqldiscussion board.
When is Google Cloud SQL be out of Limited Preview?
We are working hard to make the service generally available.We don’t have a firm date that we can announce right now.
Do you support all the features of MySQL?
In general, Google Cloud SQL supports all the features of MySQL. The following are lists of all the unsupported features and notable differences that Google Cloud SQL has from MySQL.
Unsupported Features:
- User defined functions
- MySql replication
Unsupported MySQL statements:
LOAD DATA INFILESELECT ... INTO OUTFILESELECT ... INTO DUMPFILEINSTALL PLUGIN .. SONAME ...UNINSTALL PLUGINCREATE FUNCTION ... SONAME ...
Unsupported SQL Functions:
LOAD_FILE()
Notable Differences:
-
- If you want to import databases with binary data into your Google Cloud SQL instance, you must use the
--hex-bloboption withmysqldump.Although this is not a required flag when you are using a local MySQL server instance and the MySQL command line, it is required if you want to import any databases with binary data into your Google Cloud SQL instance. For more information, see Importing Data.
- If you want to import databases with binary data into your Google Cloud SQL instance, you must use the
- How large a database can I use with Google Cloud SQL?
- Currently, in this limited preview period, your database instance must be no larger than 10GB.
- How can I be notified when there are any changes to Google Cloud SQL?
- You can sign up for the sql-announcements forum where we post announcements and news about the Google Cloud SQL.
- How can I cancel my Google Cloud SQL account?
- To remove all data from your Google Cloud SQL account and disable the service:
- Delete all your data. You can remove your tables, databases, and indexes using the
dropcommand. For more information, see SQL DROP statement. - Deactivate the Google Cloud SQL by visiting the Services pane and clicking the On button next to Google Cloud SQL. The button changes from Onto Off.
- Delete all your data. You can remove your tables, databases, and indexes using the
- How do I report a bug, request a feature, or ask a question?
- You can report bugs and request a feature on our project page.You can ask a question in our discussion forum.
Getting Started
- Can I use languages other than Java or Python?
- Only Java and Python are supported for Google Cloud SQL.
- Can I use Google Cloud SQL outside of Google App Engine?
- The Limited Preview is primarily focused on giving Google App Engine customers the ability to use a familiar relational database environment. Currently, you cannot access Google Cloud SQL from outside Google App Engine.
- What database engine are we using in the Google Cloud SQL?
- MySql Version 5.1.59
- Do I need to install a local version of MySQL to use the Development Server?
- Yes.
Managing Your Instances
- Do I need to use the Google APIs Console to use Google Cloud SQL?
- Yes. For basic tasks like granting access control to applications, creating instances, and deleting instances, you need to use the Google APIs Console.
- Can I import or export specific databases?
- No, currently it is not possible to export specific databases. You can only export your entire instance.
- Do I need a Google Cloud Storage account to import or export my instances?
- Yes, you need to sign up for a Google Cloud Storage account or have access to a Google Cloud Storage account to import or export your instances. For more information, see Importing and Exporting Data.
- If I delete my instance, can I reuse the instance name?
- Yes, but not right away. The instance name is reserved for up to two months before it can be reused.
Tools & Resources
- Can I use Django with Google Cloud SQL?
- No, currently Google Cloud SQL is not compatible with Django.
- What is the best tool to use for interacting with my instance?
- There are a variety of tools available for Google Cloud SQL. For executing simple statements, you can use the SQL prompt. For executing more complicated tasks, you might want to use the command line tool. If you want to use a tool with a graphical interface, the SQuirrel SQL Client provides an interface you can use to interact with your instance.
Common Technical Questions
- Should I use InnoDB for my tables?
- Yes. InnoDB is the default storage engine in MySQL 5.5 and is also the recommended storage engine for Google Cloud SQL. If you do not need any features that require MyISAM, you should use InnoDB. You can convert your existing tables using the following SQL command, replacing
tablenamewith the name of the table to convert:ALTER tablename ENGINE = InnoDB;
If you have a
mysqldumpfile where all your tables are in MyISAM format, you can convert them by piping the file through a sed script:mysqldump --databases database_name [-u username -p password] --hex-blob database_name | sed 's/ENGINE=MyISAM/ENGINE=InnoDB/g' > database_file.sql
Warning: You should not do this if your
mysqldumpfile contains the mysql schema. Those files must remain in MyISAM. - Are there any size or QPS limits?
- Yes, the following limits apply to Google Cloud SQL:
Resource Limits from External Requests Limits from Google App Engine Queries Per Second (QPS) 5 QPS No limit Maximum Request Size 16 MB Maximum Response Size 16 MB Google App Engine Limits
Google App Engine applications are also subject to additional Google App Engine quotas and limits. Requests from Google App Engine applications to Google Cloud SQL are subject to the following time limits:
- All database requests must finish within the HTTP request timer, around 60 seconds.
- Offline requests like cron tasks have a time limit of 10 minutes.
- Backend requests to Google Cloud SQL have a time limit of 10 minutes.
App Engine-specific quotas and access limits are discussed on the Google App Engine Quotas page.
- Should I use Google Cloud SQL with my non-High Replication App Engine application?
- We recommend that you use Google Cloud SQL with High Replication App Engine applications. While you can use use Google Cloud SQL with applications that do not use high replication, doing so might impact performance.
- Source-
- https://code.google.com/apis/sql/faq.html#supportmysqlfeatures


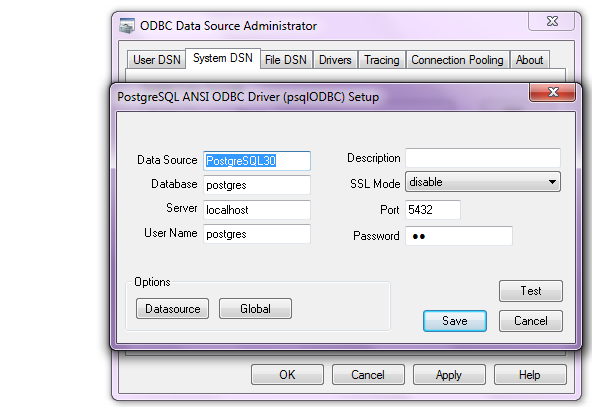
 Use the configuration options shown exactly here. The user is root, the TCP/IP Server is local host, use the same password in Step 1 and the Database is MySQL
Use the configuration options shown exactly here. The user is root, the TCP/IP Server is local host, use the same password in Step 1 and the Database is MySQL