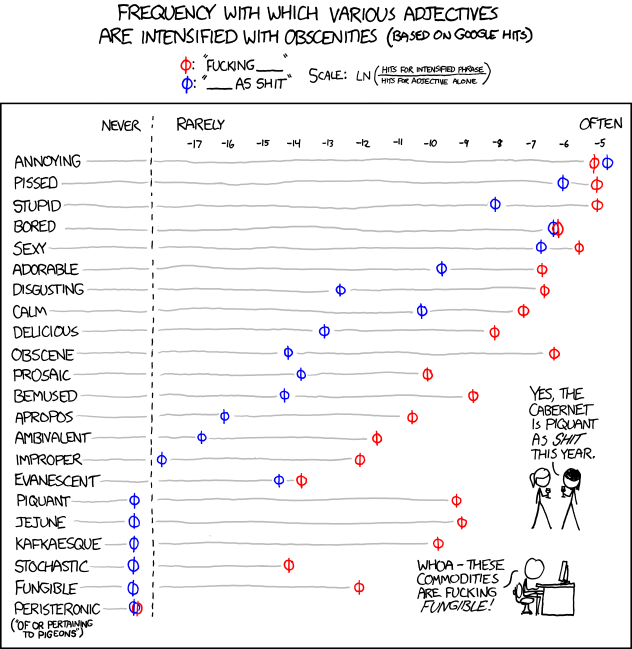
What is RFM Analysis?
Recency Frequency Monetization is basically a technique to classify your entire customer list. You may be a retail player with thousands of customers or a enterprise software seller with only two dozen customers.
RFM Analysis can help you cut through and focus on the real customer that drives your profit.
As per Wikipedia–
http://en.wikipedia.org/wiki/RFM
RFM is a method used for analyzing customer behavior and defining market segments. It is commonly used in database marketing and direct marketing and has received particular attention in retail.
RFM stands for
- Recency – How recently a customer has purchased?
- Frequency – How often he purchases?
- Monetary Value – How much does he spend?
To create an RFM analysis, one creates categories for each attribute. For instance, the Recency attribute might be broken into three categories: customers with purchases within the last 90 days; between 91 and 365 days; and longer than 365 days. Such categories may be arrived at by applying business rules, or using a data mining technique, such asCHAID, to find meaningful breaks.
—————————————————————————————————-
Even if you dont know what or how to do a RFM, see below for an easy to do way.
I just got myself an evaluation copy of a fully loaded IBM SPSS 19 Module and did some RFM Analysis on some data- the way SPSS recent version is it makes it very very useful even to non statistical tool- but an extremely useful one to a business or marketing user.
Here are some screenshots to describe the features.
1) A simple dashboard to show functionality (with room for improvement for visual appeal)
 2) Simple Intuitive design to inputting data
2) Simple Intuitive design to inputting data 3) Some options in creating marketing scorecards
3) Some options in creating marketing scorecards 4) Easy to understand features for a business audiences
4) Easy to understand features for a business audiences
rather than pseudo techie jargon 5) Note the clean design of the GUI in specifying data input type
5) Note the clean design of the GUI in specifying data input type 6) Again multiple options to export results in a very user friendly manner with options to customize business report
6) Again multiple options to export results in a very user friendly manner with options to customize business report 7) Graphical output conveniently pasted inside a word document rather than a jumble of images. Auto generated options for customized standard graphs.
7) Graphical output conveniently pasted inside a word document rather than a jumble of images. Auto generated options for customized standard graphs. 8) An attractive heatmap to represent monetization for customers. Note the effect that a scale of color shades have in visual representation of data.
8) An attractive heatmap to represent monetization for customers. Note the effect that a scale of color shades have in visual representation of data. 9) Comparative plots placed side by side with easy to understand explanation (in the output word doc not shown here)
9) Comparative plots placed side by side with easy to understand explanation (in the output word doc not shown here) 10) Auto generated scores attached to data table to enhance usage.
10) Auto generated scores attached to data table to enhance usage. 
Note here I am evaluating RFM as a marketing technique (which is well known) but also the GUI of IBM SPSS 19 Marketing Analytics. It is simple, and yet powerful into turning what used to be a purely statistical software for nerds into a beautiful easy to implement tool for business users.
So what else can you do in Marketing Analytics with SPSS 19.
IBM SPSS Direct Marketing
The Direct Marketing add-on option allows organizations to ensure their marketing programs are as effective as possible, through techniques specifically designed for direct marketing, including:
• RFM Analysis. This technique identifies existing customers who are most likely to respond to a new offer.
• Cluster Analysis. This is an exploratory tool designed to reveal natural groupings (or clusters) within your data. For example, it can identify different groups of customers based on various demographic and purchasing characteristics.
• Prospect Profiles. This technique uses results from a previous or test campaign to create descriptive profiles. You can use the profiles to target specific groups of contacts in future campaigns.
• Postal Code Response Rates. This technique uses results from a previous campaign to calculate postal code response rates. Those rates can be used to target specific postal codes in future campaigns.
• Propensity to Purchase. This technique uses results from a test mailing or previous campaign to generate propensity scores. The scores indicate which contacts are most likely to respond.
• Control Package Test. This technique compares marketing campaigns to see if there is a significant difference in effectiveness for different packages or offers.
Click here to find out more about Direct Marketing.
35.965000
-83.920000



















{kind=link}