Here is an interview with noted analytics expert Jaime Fitzgerald, of Fitzgerald Analytics.

Ajay-Describe your career journey from being a Harvard economist to being a text analytics thought leader.
Jaime- I was attracted to economics because of the logic, the structured and systematic approach to understanding the world and to solving problems. In retrospect, this is the same passion for logic in problem solving that drives my business today.
About 15 years ago, I began working in consulting and initially took a traditional career path. I worked for well-known strategy consulting firms including First Manhattan Consulting Group, Novantas LLC, Braun Consulting, and for the former Japan-focused division of Deloitte Consulting, which had spun off as an independent entity. I was the only person in their New York City office for whom Japanese was not the first language.
While I enjoyed traditional consulting, I was especially passionate about the role of data, analytics, and process improvement. In traditional strategy consulting, these are important factors, but I had a vision for a “next generation” approach to strategy consulting that would be more transparent, more robust, and more focused on the role that information, analysis, and process plays in improving business results. I often explain that while my firm is “not your father’s consulting model,” we have incorporated key best practices from traditional consulting, and combined them with an approach that is more data-centric, technology-centric, and process-centric.
At the most fundamental level, I was compelled to found Fitzgerald Analytics more than six years ago by my passion for the role information plays in improving results, and ultimately improving lives. In my vision, data is an asset waiting to be transformed into results, including profit as well as other results that matter deeply to people. For example,one of the most fulfilling aspects of our work at Fitzgerald Analytics is our support of non-profits and social entrepreneurs, who we help increase their scale and their success in achieving their goals.
Ajay- How would you describe analytics as a career option to future students. What do you think are the most essential qualities an analytics career requires.
Jaime- My belief is that analytics will be a major driver of job-growth and career growth for decades. We are just beginning to unlock the full potential of analytics, and already the demand for analytic talent far exceeds the supply.
To succeed in analytics, the most important quality is logic. Many people believe that math or statistical skills are the most important quality, but in my experience, the most essential trait is what I call “ThoughtStyle” — critical thinking, logic, an ability to break down a problem into components, into sub-parts.
Ajay -What are your favorite techniques and methodologies in text analytics. How do you see social media and Big Data analytics as components of text analytics
Jaime-We do a lot of work for our clients measuring Customer Experience, by which I mean the experience customers have when interacting with our clients. For example, we helped a major brokerage firm to measure 12 key “Moments that Matter,” including the operational aspects of customer service, customer satisfaction and sentiment, and ultimately customer behavior. Clients care about this a lot, because customer experience drives customer loyalty, which in turn drives customer behavior, customer loyalty, and customer profitability.
Text analytics plays a key role in these projects because much of our data on customer sentiment comes via unstructured text data. For example, we have access to call center transcripts and notes, to survey responses, and to social media comments.
We use a variety of methods, some of which I’m not in a position to describe in great detail. But at a high level, I would say that our favorite text analytics methodologies are “hybrid solutions” which use a two-step process to answer key questions for clients:
Step 1: convert unstructured data into key categorical variables (for example, using contextual analysis to flag users who are critical vs. neutral vs. advocates)
Step 2: linking sentiment categories to customer behavior and profitability (for example, linking customer advocacy and loyalty with customer profits as well as referral volume, to define the ROI that clients accrue for customer satisfaction improvements)
Ajay- Describe your consulting company- Fitzgerald Analytics and some of the work that you have been engaged in.
Jaime- Our mission is to “illuminate reality” using data and to convert Data to Dollars for our clients. We have a track record of doing this well, with concrete and measurable results in the millions of dollars. As a result, 100% of our clients have engaged us for more than one project: a 100% client loyalty rate.
Our specialties–and most frequent projects–include customer profitability management projects, customer segmentation, customer experience management, balanced scorecards, and predictive analytics. We are often engaged to address high-stakes analytic questions, including issues that help to set long-term strategy. In other cases, clients hire us to help them build their internal capabilities. We have helped build several brand new analytic teams for clients, which continue to generate millions of dollars of profits with their fact-based recommendations.
Our methodology is based on Steven Covey’s principle: “begin with the end in mind,” the concept of starting with the client’s goal and working backwards from there. I often explain that our methods are what you would have gotten if Steven Covey had been a data analyst…we are applying his principles to the world of data analytics.
Ajay- Analytics requires more and more data while privacy requires the least possible data. What do you think are the guidelines that need to be built in sharing internet browsing and user activity data and do we need regulations just like we do for sharing financial data.
Jaime- Great question. This is an essential challenge of the big data era. My perspective is that firms who depend on user data for their analysis need to take responsibility for protecting privacy by using data management best practices. Best practices to adequately “mask” or remove private data exist…the problem is that these best practices are often not applied. For example, Facebook’s practice of sharing unique user IDs with third-party application companies has generated a lot of criticism, and could have been avoided by applying data management best practices which are well known among the data management community.
If I were able to influence public policy, my recommendation would be to adopt a core set of simple but powerful data management standards that would protect consumers from perhaps 95% of the privacy risks they face today. The number one standard would be to prohibit sharing of static, personally identifiable user IDs between companies in a manner that creates “privacy risk.” Companies can track unique customers without using a static ID…they need to step up and do that.
Ajay- What are your favorite text analytics software that you like to work with.
Jaime- Because much of our work in deeply embedded into client operations and systems, we often use the software our clients already prefer. We avoid recommending specific vendors unless our client requests it. In tandem with our clients and alliance partners, we have particular respect for Autonomy, Open Text, Clarabridge, and Attensity.
Biography-
http://www.fitzgerald-analytics.com/jaime_fitzgerald.html
The Founder and President of Fitzgerald Analytics, Jaime has developed a distinctively quantitative, fact-based, and transparent approach to solving high stakes problems and improving results. His approach enables translation of Data to Dollars™ using methodologies clients can repeat again and again. He is equally passionate about the “human side of the equation,” and is known for his ability to link the human and the quantitative, both of which are needed to achieve optimal results.
Experience: During more than 15 years serving clients as a management strategy consultant, Jaime has focused on customer experience and loyalty, customer profitability, technology strategy, information management, and business process improvement. Jaime has advised market-leading banks, retailers, manufacturers, media companies, and non-profit organizations in the United States, Canada, and Singapore, combining strategic analysis with hands-on implementation of technology and operations enhancements.
Career History: Jaime began his career at First Manhattan Consulting Group, specialists in financial services, and was later a Co-Founder at Novantas, the strategy consultancy based in New York City. Jaime was also a Manager for Braun Consulting, now part of Fair Isaac Corporation, and for Japan-based Abeam Consulting, now part of NEC.
Background: Jaime is a graduate of Harvard University with a B.A. in Economics. He is passionate and supportive of innovative non-profit organizations, their effectiveness, and the benefits they bring to our society.
Upcoming Speaking Engagements: Jaime is a frequent speaker on analytics, information management strategy, and data-driven profit improvement. He recently gave keynote presentations on Analytics in Financial Services for The Data Warehousing Institute, the New York Technology Council, and the Oracle Financial Services Industry User Group. A list of Jaime’s most interesting presentations on analyticscan be found here.
He will be presenting a client case study this fall at Text Analytics World re: “New Insights from ‘Big Legacy Data’: The Role of Text Analytics”
Connecting with Jaime: Jaime can be found at  Linkedin, and
Linkedin, and  Twitter. He edits the Fitzgerald Analytics Blog.
Twitter. He edits the Fitzgerald Analytics Blog.

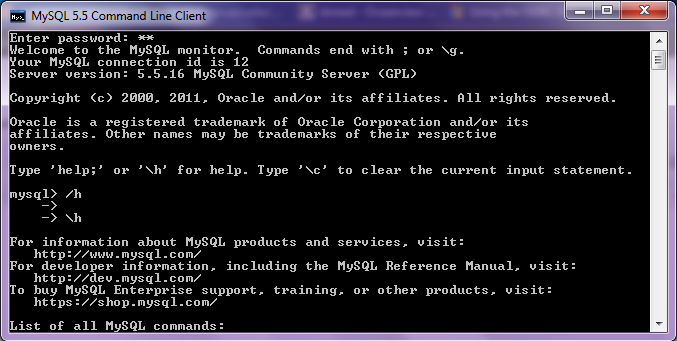


 Use the configuration options shown exactly here. The user is root, the TCP/IP Server is local host, use the same password in Step 1 and the Database is MySQL
Use the configuration options shown exactly here. The user is root, the TCP/IP Server is local host, use the same password in Step 1 and the Database is MySQL