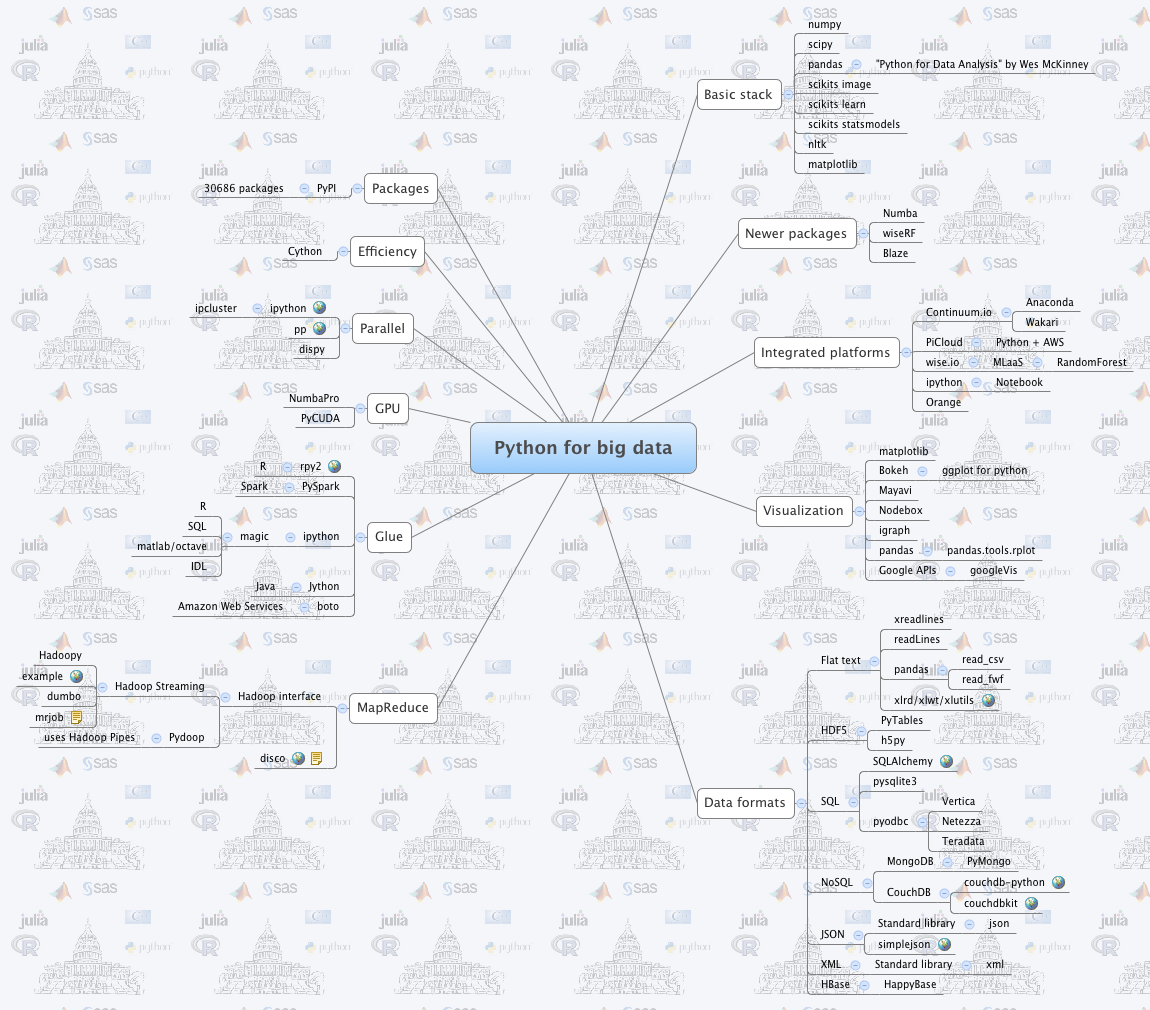
In the future I think analysts need to be polyglots- you will need to know more than one language for crunching data.
SAS, Python, R, Julia,SPSS,Matlab- Pick Any Two 😉 or Any Three.
No, you can’t count C or Java as a statistical language 🙂 🙂
Efforts to promote Polyglots in Statistical Software are-
1) R for SAS and SPSS Users (free or book)
- JMP and R reference http://www.jmp.com/support/help/Working_with_R.shtml
2) R for Stata Users (book)
4) Using Python and R together
- Accessing R from Python (Rpy2) http://www.bytemining.com/wp-content/uploads/2010/10/rpy2.pdf
- Big Data with R and Python (though these have been made separately)
- Python for Data Analysis is a book .
Python for Data Analysis by Wes McKinney
Probably we need a Python and R for Data Analysis book- just like we have for SAS and R books.
- The RPy2 documentation is handy http://rpy.sourceforge.net/rpy2/doc-2.1/html/introduction.html
- A nice tutorial is also here – also the inspiration to writing this post http://files.meetup.com/1225993/Laurent%20Gautier_R_toPython_bridge_to_R.pdf#!
5) Matlab and R
Reference (http://mathesaurus.sourceforge.net/matlab-python-xref.pdf ) includes Python
5) Octave and R
package http://cran.r-project.org/web/packages/RcppOctave/vignettes/RcppOctave.pdf includes Matlab
reference http://cran.r-project.org/doc/contrib/R-and-octave.txt
6) Julia and python
- Julia and IPython https://github.com/JuliaLang/IJulia.jl
- PyPlot uses the Julia PyCall package to call Python’s matplotlib directly from Julia
7) SPSS and Python is here
8) SPSS and R is as below
- The Essentials for R for Statistics versions 22, 21, 20, and 19 are available here.
- This link will take you to the SourceForge site where the Version 18 Essentials and Plugins are hosted.
9) Using R from Clojure – Incanter
Use embedded R from Clojure and Incanter http://github.com/jolby/rincanter
 NumPy is the fundamental package needed for scientific computing with Python. Besides its obvious scientific uses, NumPy can also be used as an efficient multi-dimensional container of generic data. Arbitrary data-types can be defined. This allows NumPy to seamlessly and speedily integrate with a wide variety of databases. Repositories for NumPy binaries:
NumPy is the fundamental package needed for scientific computing with Python. Besides its obvious scientific uses, NumPy can also be used as an efficient multi-dimensional container of generic data. Arbitrary data-types can be defined. This allows NumPy to seamlessly and speedily integrate with a wide variety of databases. Repositories for NumPy binaries:  SciPy is open-source software for mathematics, science, and engineering. It is also the name of a very popular conference on scientific programming with Python. The SciPy library depends on NumPy, which provides convenient and fast N-dimensional array manipulation. The SciPy library is built to work with NumPy arrays, and provides many user-friendly and efficient numerical routines such as routines for numerical integration and optimization.
SciPy is open-source software for mathematics, science, and engineering. It is also the name of a very popular conference on scientific programming with Python. The SciPy library depends on NumPy, which provides convenient and fast N-dimensional array manipulation. The SciPy library is built to work with NumPy arrays, and provides many user-friendly and efficient numerical routines such as routines for numerical integration and optimization. 2D plotting library for Python that produces high quality figures that can be used in various hardcopy and interactive environments. matplolib is compatiable with python scripts and the python and ipython shells.
2D plotting library for Python that produces high quality figures that can be used in various hardcopy and interactive environments. matplolib is compatiable with python scripts and the python and ipython shells. High quality open source python shell that includes tools for high level and interactive parallel computing.
High quality open source python shell that includes tools for high level and interactive parallel computing. SymPy is a Python library for symbolic mathematics. It aims to become a full-featured computer algebra system (CAS) while keeping the code as simple as possible in order to be comprehensible and easily extensible. SymPy is written entirely in Python and does not require any external libraries.
SymPy is a Python library for symbolic mathematics. It aims to become a full-featured computer algebra system (CAS) while keeping the code as simple as possible in order to be comprehensible and easily extensible. SymPy is written entirely in Python and does not require any external libraries. Cython is a language based on Pyrex that makes writing C extensions for Python as easy as writing them in Python itself. Cython supports calling C functions and declaring C types on variables and class attributes, allowing the compiler to generate very efficient C code from Cython code.
Cython is a language based on Pyrex that makes writing C extensions for Python as easy as writing them in Python itself. Cython supports calling C functions and declaring C types on variables and class attributes, allowing the compiler to generate very efficient C code from Cython code. pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language. Free high-quality and peer-reviewed volunteer produced collection of algorithms for image processing.
Free high-quality and peer-reviewed volunteer produced collection of algorithms for image processing. Module designed for scientific pythons that provides accesible solutions to machine learning problems.
Module designed for scientific pythons that provides accesible solutions to machine learning problems. Statsmodels is a Python package that provides a complement to scipy for statistical computations including descriptive statistics and estimation of statistical models.
Statsmodels is a Python package that provides a complement to scipy for statistical computations including descriptive statistics and estimation of statistical models. Interactive development environment for Python that features advanced editing, interactive testing, debugging and introspection capabilities, as well as a numerical computing environment made possible through the support of Ipython, NumPy, SciPy, and matplotlib.
Interactive development environment for Python that features advanced editing, interactive testing, debugging and introspection capabilities, as well as a numerical computing environment made possible through the support of Ipython, NumPy, SciPy, and matplotlib. Open source mathematics sofware system that combines existing open-source packages into a Python-based interface.
Open source mathematics sofware system that combines existing open-source packages into a Python-based interface. Free scientific and engineering development software used for numerical computations, and analysis and visualization of data using the Python programmimg language.
Free scientific and engineering development software used for numerical computations, and analysis and visualization of data using the Python programmimg language.