Here is an interview with Dr Ian Fellows, creator of acclaimed packages in R like Deducer and the Founder and President of
Fellstat.comAjay- Describe your involvement with the Deducer Project, and the various plugins associated with it. What has been the usage and response for Deducer from R Community.
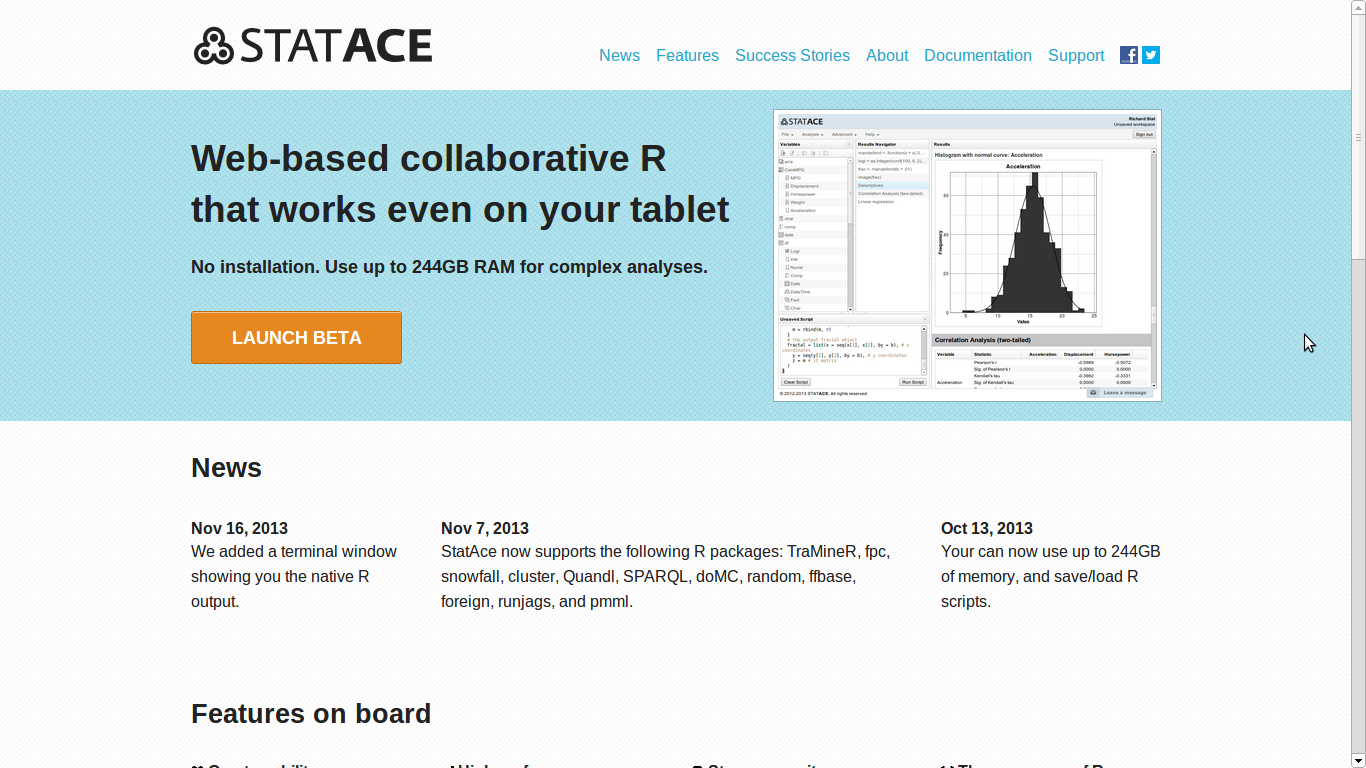
Ian- Deducer is a graphical user interface for data analysis built on R. It sprung out of a disconnect between the toolchain used by myself and the toolchain of the psychologists that I worked with at the University of California, San DIego. They were primarily SPSS user, whereas I liked to use R, especially for anything that was not a standard analysis.
I felt that there was a big gap in the audience that R serves. Not all consumers or producers of statistics can be expected to have the computational background (command-line programming) that R requires. I think it is important to recognize and work with the areas of expertise that statistical users have. I’m not an expert in psychology, and they didn’t expect me to be one. They are not experts in computation, and I don’t think that we should expect them to be in order to be a part of the R toolchain community.

This was the impetus behind Deducer, so it is fundamentally designed to be a familiar experience for users coming from an SPSS background and provides a full implementation of the standard methods in statistics, and data manipulation from descriptives to generalized linear models. Additionally, it has an advanced GUI for creating visualizations which has been well received, and won the John Chambers award for statistical software in 2011.
Uptake of the system is difficult to measure as CRAN does not track package downloads, but from what I can tell there has been a steadily increasing user base. The online manual has been accessed by over 75,000 unique users, with over 400,000 page views. There is a small, active group of developers creating add-on packages supporting various sub-diciplines of statistics. There are 8 packages on CRAN extending/using Deducer, and quite a few more on r-forge.
Ajay- Do you see any potential for Deducer as an enterprise software product (like R Studio et al)
Ian- Like R Studio, Deducer is used in enterprise environments but is not specifically geared towards that environment. I do see potential in that realm, but don’t have any particular plan to make an enterprise version of Deducer.
Ajay- Describe your work in Texas Hold’em Poker. Do you see any potential for R for diversifying into the casino analytics – which has hitherto been served exclusively by non open source analytics vendors.
Ian- As a Statistician, I’m very much interested in problems of inference under uncertainty, especially when the problem space is huge. Creating an Artificial Intelligence that can play (heads-up limit) Texas Hold’em Poker at a high level is a perfect example of this. There is uncertainty created by the random drawing of cards, the problem space is 10^{18}, and our opponent can adapt to any strategy that we employ.
While high level chess A.I.s have existed for decades, the first viable program to tackle full scale poker was introduced in 2003 by the incomparable Computer Poker Research group at the University of Alberta. Thus poker represents a significant challenge which can be used as a test bed to break new ground in applied game theory. In 2007 and 2008 I submitted entries to the AAA’s annual computer poker competition, which pits A.I.s from universities across the world against each other. My program, which was based on an approximate game theoretic equilibrium calculated using a co-evolutionary process called fictitious play, came in second behind the Alberta team.
Ajay- Describe your work in social media analytics for R. What potential do you see for Social Network Analysis given the current usage of it in business analytics and business intelligence tools for enterprise.
Ian- My dissertation focused on new model classes for social network analysis (
http://arxiv.org/pdf/1208.0121v1.pdf and
http://arxiv.org/pdf/1303.1219.pdf). R has a great collection of tools for social network analysis in the statnet suite of packages, which represents the forefront of the literature on the statistical modeling of social networks. I think that if the analytics data is small enough for the models to be fit, these tools can represent a qualitative leap in the understanding and prediction of user behavior.
Most uses of social networks in enterprise analytics that I have seen are limited to descriptive statistics (what is a user’s centrality; what is the degree distribution), and the use of these descriptive statistics as fixed predictors in a model. I believe that this approach is an important first step, but ignores the stochastic nature of the network, and the dynamics of tie formation and dissolution. Realistic modeling of the network can lead to more principled, and more accurate predictions of the quantities that enterprise users care about.
The rub is that the Markov Chain Monte Carlo Maximum Likelihood algorithms used to fit modern generative social network models (such as exponential-family random graph models) do not scale well at all. These models are typically limited to fitting networks with fewer than 50,000 vertices, which is clearly insufficient for most analytics customers who have networks more on the order of 50,000,000.
This problem is not insoluble though. Part of my ongoing research involves scalable algorithms for fitting social network models.
Ajay- You decided to go from your Phd into consulting (www.fellstat.com) . What were some of the options you considered in this career choice.
Ian– I’ve been working in the role of a statistical consultant for the last 7 years, starting as an in-house consultant at UCSD after obtaining my MS. Fellows Statistics has been operating for the last 3 years, though not fulltime until January of this year. As I had already been consulting, it was a natural progression to transition to consulting fulltime once I graduated with my Phd.
This has allowed me to both work on interesting corporate projects, and continue research related to my dissertation via sub-awards from various universities.
Ajay- What does Fellstat.com offer in its consulting practice.
Ian– Fellows Statistics offers personalized analytics services to both corporate and academic clients. We are a boutique company, that can scale from a single statistician to a small team of analysts chosen specifically with the client’s needs in mind. I believe that by being small, we can provide better, close-to-the-ground responsive service to our clients.
As a practice, we live at the intersection of mathematical sophistication, and computational skill, with a hint of UI design thrown into the mix. Corporate clients can expect a diverse range of analytic skills from the development of novel algorithms to the design and presentation of data for a general audience. We’ve worked with Revolution Analytics developing algorithms for their ScaleR product, the Center for Disease Control developing graphical user interfaces set to be deployed for world-wide HIV surveillance, and Prospectus analyzing clinical trial data for retinal surgery. With access to the cutting edge research taking place in the academic community, and the skills to implement them in corporate environments, Fellows Statistics is able to offer clients world-class analytics services.
Ajay- How does big data affect the practice of statistics in business decisions.
Ian– There is a big gap in terms of how the basic practice of statistics is taught in most universities, and the types of analyses that are useful when data sizes become large. Back when I was at UCSD, I remember a researcher there jokingly saying that everything is correlated rho=.2. He was joking, but there is a lot of truth to that statement. As data sizes get larger everything becomes significant if a hypothesis test is done, because the test has the power to detect even trivial relationships.
Ajay- How is the R community including developers coping with the Big Data era? What do you think R can do more for Big Data?
Ian- On the open source side, there has been a lot of movement to improve R’s handling of big data. The bigmemory project and the ff package both serve to extend R’s reach beyond in-memory data structures. Revolution Analytics also has the ScaleR package, which costs money, but is lightning fast and has an ever growing list of analytic techniques implemented. There are also several packages integrating R with hadoop.
Ajay- Describe your research into data visualization including word cloud and other packages. What do you think of Shiny, D3.Js and online data visualization?
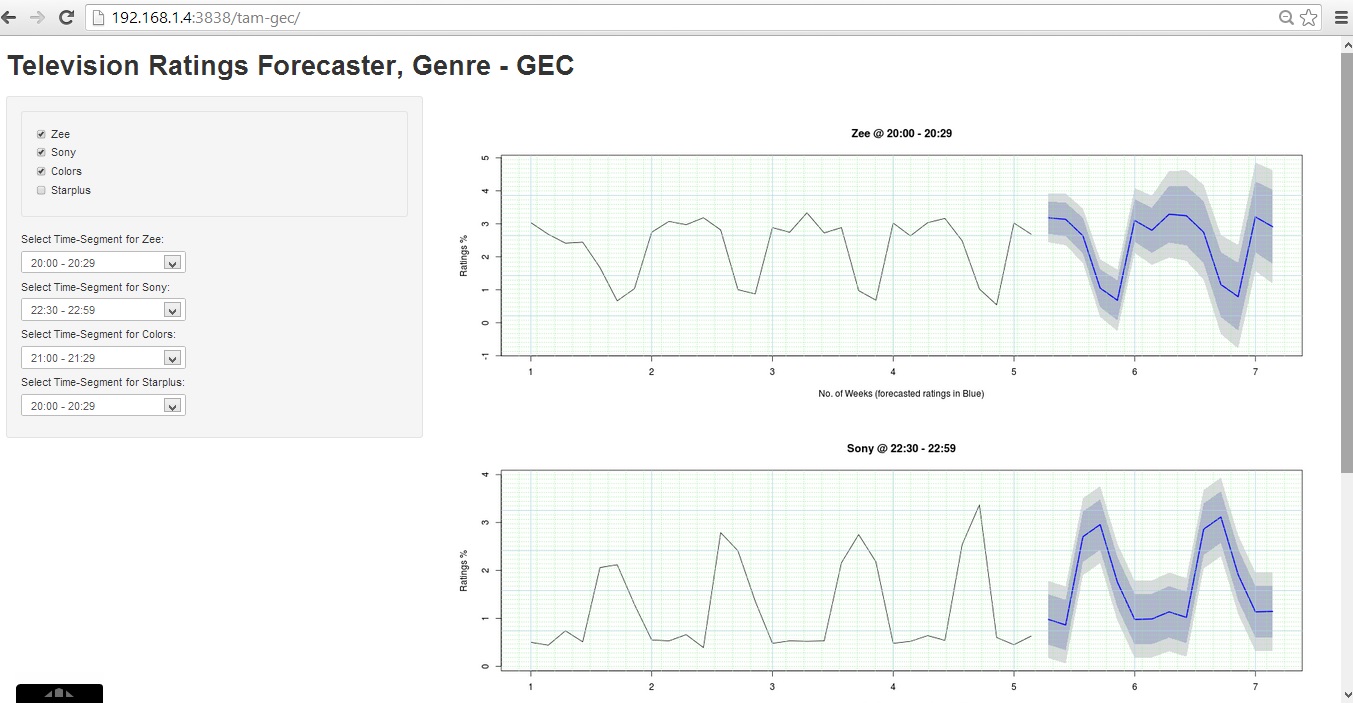
Ian- I recently had the opportunity to delve into d3.js for a client project, and absolutely love it. Combined with Shiny, d3 and R one can very quickly create a web visualization of an R modeling technique. One limitation of d3 is that it doesn’t work well with internet explorer 6-8. Once these browsers finally leave the ecosystem, I expect an explosion of sites using d3.
Ajay- Do you think wordcloud is an overused data visualization type and how can it be refined?
Ian- I would say yes, but not for the reasons you would think. A lot of people criticize word clouds because they convey the same information as a bar chart, but with less specificity. With a bar chart you can actually see the frequency, whereas you only get a relative idea with word clouds based on the size of the word.
I think this is both an absolutely correct statement, and misses the point completely. Visualizations are about communicating with the reader. If your readers are statisticians, then they will happily consume the bar chart, following the bar heights to their point on the y-axis to find the frequencies. A statistician will spend time with a graph, will mull it over, and consider what deeper truths are found there. Statisticians are weird though. Most people care as much about how pretty the graph looks as its content. To communicate to these people (i.e. everyone else) it is appropriate and right to sacrifice statistical specificity to design considerations. After all, if the user stops reading you haven’t conveyed anything.
But back to the question… I would say that they are over used because they represent a very superficial analysis of a text or corpus. The word counts do convey an aspect of a text, but not a very nuanced one. The next step in looking at a corpus of texts would be to ask how are they different and how are they the same. The wordcloud package has the comparison and commonality word clouds, which attempt to extend the basic word cloud to answer these questions (see:
http://blog.fellstat.com/?p=101).
About-
Dr. Ian Fellows is a professional statistician based out of the University of California, Los Angeles. His research interests range over many sub-disciplines of statistics. His work in statistical visualization won the prestigious John Chambers Award in 2011, and in 2007-2008 his Texas Hold’em AI programs were ranked second in the world.
Applied data analysis has been a passion for him, and he is accustomed to providing accurate, timely analysis for a wide range of projects, and assisting in the interpretation and communication of statistical results. He can be contacted at info@fellstat.com
28.635308
77.224960