Over the past few years I have chosen a few tools primarily driven from Psychology to help me manage complex scenarios, difficult clients and problematic questions. The reason for this is quite simple, data science especially predictive analytics is trying to mimic or predict human behavior which is inherently irrational and driven by impulse or need fulfillment. However when human behavior is aggregated as well as segregated we can predict it but for short periods of time after which predictive models decay.
- Johari’s Window – source https://en.wikipedia.org/wiki/Johari_window

philosopher Charles Handy calls this concept the Johari House with four rooms. Room 1 is the part of ourselves that we see and others see. Room 2 is the aspects that others see but we are not aware of. Room 4 is the most mysterious room in that the unconscious or subconscious part of us is seen by neither ourselves nor others. Room 3 is our private space, which we know but keep from others.
Open or Arena: Adjectives that are selected by both the participant and his or her peers are placed into the Open or Arenaquadrant. This quadrant represents traits of the subjects that both they and their peers are aware of.
Hidden or Façade: Adjectives selected only by subjects, but not by any of their peers, are placed into the Hidden or Façadequadrant, representing information about them their peers are unaware of. It is then up to the subject to disclose this information or not.
Blind : Adjectives that are not selected by subjects but only by their peers are placed into the Blind Spot quadrant. These represent information that the subject is not aware of, but others are, and they can decide whether and how to inform the individual about these “blind spots“.
Unknown: Adjectives that were not selected by either subjects or their peers remain in the Unknown quadrant, representing the participant’s behaviors or motives that were not recognized by anyone participating.
2) Hierarchy of Needs Source- https://en.wikipedia.org/wiki/Maslow%27s_hierarchy_of_needs
Maslow used the terms “physiological”, “safety”, “belongingness” and “love”, “esteem”, “self-actualization”, and “self-transcendence” to describe the pattern that human motivations generally move through.

This helps me understand what a client wants with a particular project and what an employee wants when he asks for pay /stock options etc
3) Agency – Owner conflict source- https://en.wikipedia.org/wiki/Principal%E2%80%93agent_problem
The principal–agent problem (also known as agency dilemma or theory of agency) occurs when one person or entity (the “agent“) is able to make decisions on behalf of, or that impact, another person or entity: the “principal“. The dilemma exists because sometimes the agent is motivated to act in his own best interests rather than those of the principal. The agent-principal relationship is a useful analytic tool in political science and economics, but may also apply to other areas.
Common examples of this relationship include corporate management (agent) and shareholders (principal), or politicians (agent) and voters (principal).[1] For another example, consider a dental patient (the principal) wondering whether his dentist (the agent) is recommending expensive treatment because it is truly necessary for the patient’s dental health, or because it will generate income for the dentist.

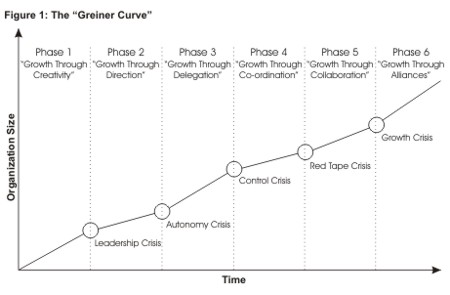
4) Culture of an organization -It changes with time. This graph helps me understand
5) Cognitive Biases- why do rational people make irrational choices. Aha! Cognitive Biases Source-https://en.wikipedia.org/wiki/Cognitive_bias
Cognitive biases are tendencies to think in certain ways that can lead to systematic deviations from a standard of rationality or good judgment, and are often studied in psychology and behavioral economics.
Among the “cold” biases,
- some involve a decision or judgement being affected by irrelevant information (for example the framing effect where the same problem receives different responses depending on how it is described; or the distinction bias where choices presented together have different outcomes than those presented separately)
- others give excessive weight to an unimportant but salient feature of the problem (e.g., anchoring)
6) Logical Fallacies- To quickly separate signal from human generated noise or arguments, I wish there was a machine learning algorithm to detect logical fallacies in NLTP.
7) Motivation (from Sanskrit) source- http://chanakya.brainhungry.com/saam-daam-dand-bhed-chanakya-neeti/
There are four ways of making someone to do a task, stated as “Saam, Daam, Dand & Bhed”. This sutra by Acharya Chanakya is used worldwide. why? It works and is highly practical. It means:
- Saam: to advice and ask
- Daam: to offer and buy
- Dand: to punish
- Bhed: exploiting the secrets
Apart from these I also use some seven strategy models for actually understanding business . I learnt in Business School- they are here in quasi -graphical easy to understand format
https://decisionstats.com/2013/12/19/business-strategy-models/









The lack of activity on rmr2 reflects maturity of the package and a shift away from Hadoop mapreduce toward spark. Please check the dplyr.spark package on github. It’s the easiest way to run spark bar none, including python, in its author very biased opinion. Example: find the best and worst flight by arrival delay on each day:
group_by(flights, year, month, day) %>%
select(flight, arr_delay) %>%
filter(arr_delay == min(arr_delay) || arr_delay == max(arr_delay))
Runs on spark, scales to whatever your cluster can store. Please show me the equivalent in any other language, python included. I am waiting.