
As part of my research for Python for R Users: A Data Science Approach (Wiley 2016) Here is an interview with Skipper Seabold, creator of statsmodels, Python package. Statsmodels is a Python module that allows users to explore data, estimate statistical models, and perform statistical tests. Since I have been playing actively with this package, I have added some screenshots to show it is a viable way to build regression models.

Ajay (A)- What prompted you to create Stats Models package?
Skipper (S) I was casting about for an open source project that I could take on to help further my programming skills during my graduate studies. I asked one of my professors who is involved in the Python community for advice. He urged that I look into the Google Summer of Code program under the SciPy project. One of the potential projects was resurrecting some code that used to be in scipy as scipy.stats.models. Getting involved in this project was a great way to strengthen my understanding of econometrics and statistics during my graduate studies. I raised the issue on the scipy mailing list, found a mentor in my co-lead developer Josef Perktold, and we started working in earnest on the project in 2009.
A- What has been the feedback from users so far?
S- Feedback has generally been pretty good. I think people now see that Python is a not only viable but also compelling alternative to R for doing statistics and econometric research as well as applied work.
A- What is your roadmap for Stats Models going forward ?
S- Our roadmap going forward is not much more than continuing to merge good code contributions, working through our current backlog of pull requests, and contuing to work on consistency of naming and API in the package for a better overall user experience. Each developer mainly works on their own research interests for new functionality, such as state-space modeling, survival modeling, statistical testing, high dimensional models, and models for big data.
There has been some expressed interest in developing a kind of plugin system such that community contributions are easier, a more regular release cycle, and merging some long-standing, large pull requests such as exponential smoothing and panel data models.
A- How do you think statsmodels compares with R packages like car and others from https://cran.r-project.org/web/views/Econometrics.html . What are the advantages if any of using Python for building the model than R
S- You could use statsmodels for pretty much any level of applied or pure econometrics research at the moment. We have implementations of discrete choice models, generalized linear models, time-series and state-space models, generalized method of moments, generalized estimating equations, nonparametric models, and support for instrumental variables regression just to pick a few areas of overlap. We provide most of the core components that you are going to find in R. Some of these components may still be more on the experimental side or may be less polished than their R counterparts. Newer functionality could use more user feedback and API design though given that some of these R packages have seen more use, but the implementations are mostly there.
One of the main advantages I see to doing statistical modeling in Python over R are in terms of the community and the experience gained. There’s a huge diversity of backgrounds in the Python community from web developers to computer science researchers to engineers and statisticians. Those doing statistics in Python are able to benefit from this larger Python community. I often see more of a focus on unit testing, API design, and writing maintainable, readable code in Python rather than R. I would also venture to say that the Python community is a little friendlier to those new to programming in terms of the people and the language. While the former isn’t strictly true now that we have stack overflow, the R mailing lists have the reputation of being very unforgiving places. As far as the latter, things like the prevalent generic-function object-oriented style and features like non-standard evaluation are really nice for an experienced R user, but they can be a little opaque and daunting for beginners in my opinion.
That said, I don’t really see R and Python as competitors. I’m an R user and think that the R language provides a wonderful environment for doing interactive statistical computing. There are also some awesome tools like RStudio and Shiny. When it comes down to it both R and Python are most often wrappers around C, C++, and Fortran code and the interactive computing language that you use is largely a matter of personal preference.
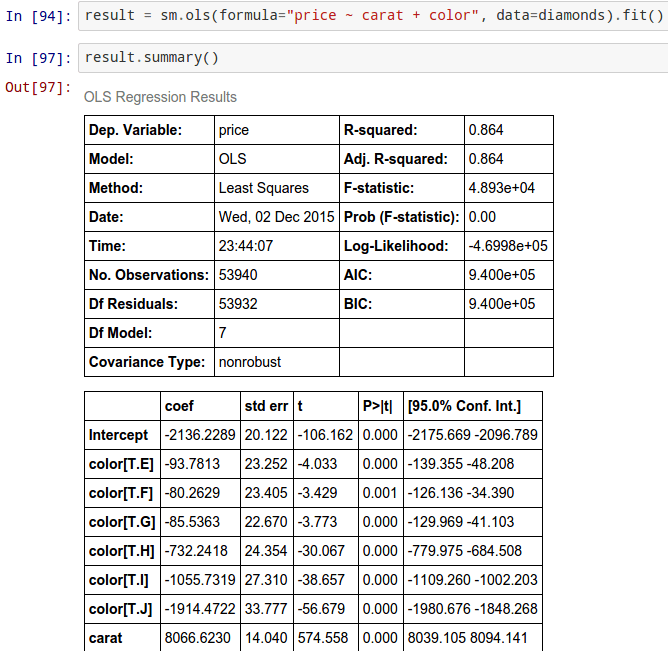
Example 1 – Statsmodels in action on diamonds dataset
A- How well is statsmodels integrated with Pandas, sci-kit learn and other Python Packages?
S- Like any scientific computing package in Python, statsmodels relies heavily on numpy and scipy to implement most of the core statistical computations.
Statsmodels integrates well with pandas. I was both an early user and contributor to the pandas project. We have had for years a system for statsmodels such that if a user supplies data structures from pandas to statsmodels, then all relevant information will be preserved and users will get back pandas data structures as results.
Statsmodels also leverages the patsy project to provide a formula framework inspired by that of S and R.
Statsmodels is also used by other projects such as seaborn to provide the number-crunching for the statistical visualizations provided.
As far as scikit-learn, though I am a heavy user of the package, so far statsmodels has not integrated well with it out of the box. We do not implement the scikit-learn API, though I have some proof of concept code that turns the statistical estimators in statsmodels into scikit-learn estimators.
We are certainly open to hearing about use cases that tighter integration would enable, but the packages often have different focuses. Scikit-learn focuses more on things like feature selection and prediction. Statsmodels is more focused on model inference and statistical tests. We are interested in continuing to explore possible integrations with the scikit-learn developers.
A- How effective is Stats Models for creating propensity models, or say logit models for financial industry or others. Which industry do you see using Pythonic statistical modeling the most.
S- I have used statsmodels to do propensity score matching and we have some utility code for this, but it hasn’t been a major focus for the project. Much of the driving force for statsmodels has been the research needs of the developers given our time constraints. This is an area we’d be happy to have contributions in.
All of the core, traditional classification algorithms are implemented in statsmodels with proper post-estimation results that you would expect from a statistical package.
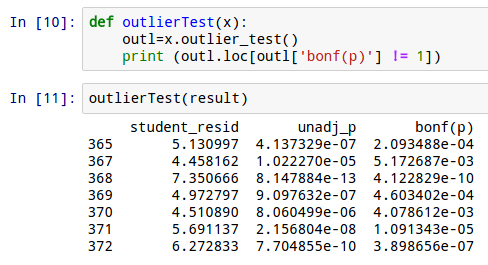
Example 2 – Statsmodels in action on Boston dataset outliers
As far as particular industries, it’s not often clear where the project is being used outside of academics. Most of our core contributors are from academia, as far as I know. I think there is certainly some use of the time-series modeling capabilities in finance, and I know people are using logistic regression for classification and inference. I work as a data scientist, and I see many data scientists using the package in a variety of projects from marketing to churn modeling and forecasting. We’re always interested to hear from people in industry about how they’re using statsmodels or looking for contributions that could make the project work better for their use cases.
About-
Skipper Seabold is a data scientist at Civis Analytics.
Before joining Civis, Skipper was a software engineer and data scientist at DataPad, Inc. He is in the final stages of a PhD in economics from American University in Washington, DC . He is the creator of statsmodels package in Python.



