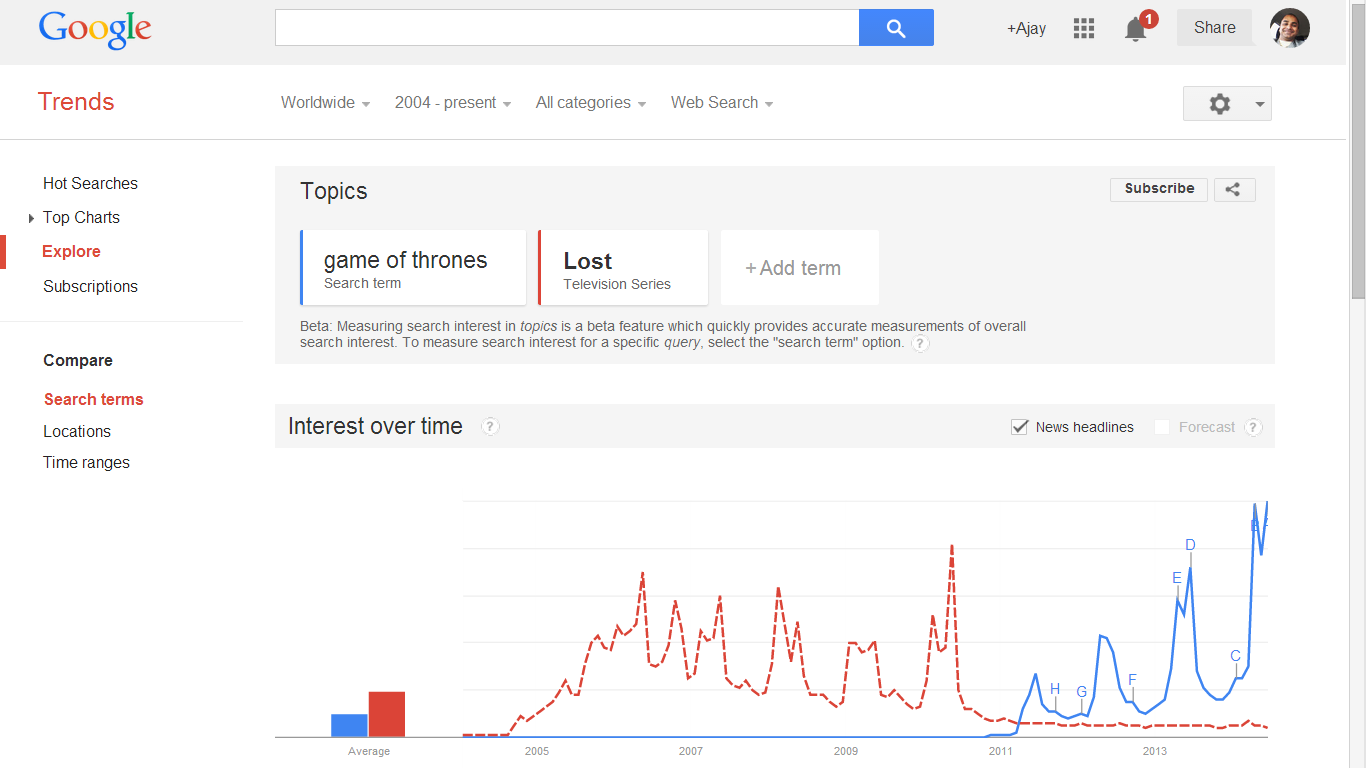
From naming the algorithm after himself ( PageRank ?) to forsaking his professors at Stanford ( who legally own the rights to many intellectual property), to first learning under Eric Schmidt and then pushing him out on the pretense of a political appointment to never came, to the era of silent cooperation with the US Government, to collecting a lot of data by assessing the risk of litigation (especially mobile), and to push intellectual property rights between open source and patent rights, to massive expensive lobbying and now even sidelining his brother in arms- Larry Page has emerged as the most ruthless combination of business savvy and formidable technological skills since Bill Gates.
He now owns a representative sample of nearly all the data on video (Youtube) , email (Gmail), website analytics ( Google Analytics), search engine (Google.com), advertising clicks ( Adwords and Adsense), a majority of mobile phones (Android).
And he wants more. To collect data from your thermostat. Your glasses. His government will not file an anti trust case because of national security. As an extension of US foreign policy, he will lead protests against Chinese hackers, censorship and even abandon the market than comply with Chinese Law, but he will gladly pay fines and delete links to comply with European Law.
There are ways to make money that are not evil. But they do not teach what is evil or not, at Stanford. Not even to dropouts.