
Happy Holidays

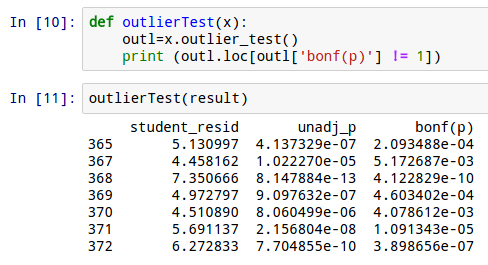
As part of my research for Python for R Users: A Data Science Approach (Wiley 2016) Here is an interview with Skipper Seabold, creator of statsmodels, Python package. Statsmodels is a Python module that allows users to explore data, estimate statistical models, and perform statistical tests. Since I have been playing actively with this package, I have added some screenshots to show it is a viable way to build regression models.

Ajay (A)- What prompted you to create Stats Models package?
A- What has been the feedback from users so far?
A- What is your roadmap for Stats Models going forward ?
A- How do you think statsmodels compares with R packages like car and others from https://cran.r-project.org/web/views/Econometrics.html . What are the advantages if any of using Python for building the model than R
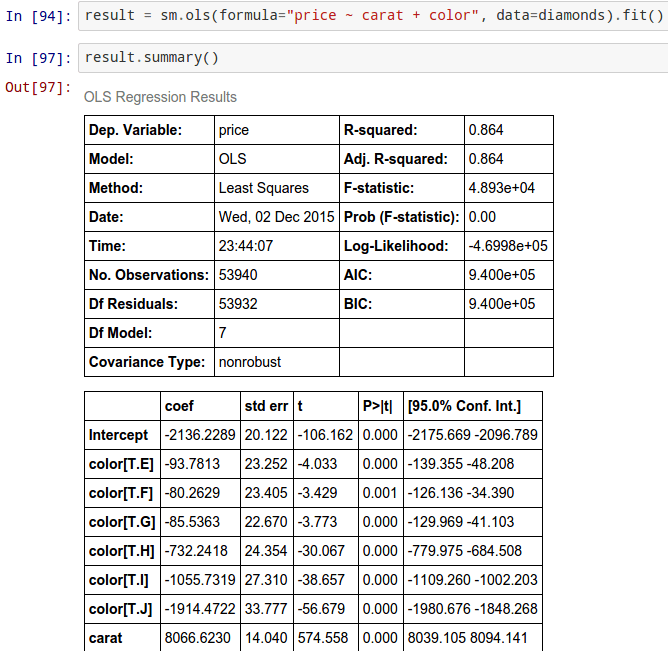
A- How well is statsmodels integrated with Pandas, sci-kit learn and other Python Packages?
A- How effective is Stats Models for creating propensity models, or say logit models for financial industry or others. Which industry do you see using Pythonic statistical modeling the most.
http://www.sas.com/en_us/learn/academy-data-science.html
SAS just launched a very nicely stacked set of two courses for its new data science program. It’s a trifle premium priced and as of now dependent only on it’s own SAS platform but the curriculum and the teaching sound very good. SAS has been around for some time, and no one ever had to worry about a job after getting trained in SAS language.
They are two six week instructor-led courses and it seems they are just tweaking details with a soft launch but it is promising for things to come. Perhaps companies like IBM and SAP et al will follow up on this initiative to CREATE more data scientists as well as UPDATE software in data science 😉
Build on your basic programming knowledge by learning to gather and analyze big data in SAS. This intensive six-week, level-one bootcamp focuses on big data management, data quality and visual data exploration for advanced analytics, and prepares you for the big data certification exams.*
Expand your big data certification skill set in our six-week data science bootcamp. This level-two program focuses on analytical modeling, machine learning, model deployment and automation, and critical communication skills. It also prepares you for the data science certification exams.*

What if the life you were meant to live never existed except as a figment or your own imagination? What if asking yourself rhetorical questions was the only life you were meant to live. Had I not got a pain in my neck precipitating my getting up and rubbing ointment in it, and writing this post as an exercise in insomniac purging- where would these thoughts go. What if the best ideas that humanity got – individually and in toto were flushed down the toilet everyday because we were too busy compromising for five more minutes of sleep. for five more dollars per hour. for five more years with the unhappy relationship. What if I supposed to write movie scripts that moved millions to laughs and tears instead of writing books a few hundred would read and posts for a few thousand more.
Ever think about the jobs you took for money. You compromised with your own self your own satisfaction and your own conscience. Think about the jobs you took for satisfaction turning down the money. You compromised with your brain, sense of logic the little voice in your head saying hey dumb arse, stop being so egoistic. The girl you saw at the cafe whom you felt was your divine soul but never said hello to because you were afraid to making a fool of yourself.
The compromises we make are the unhappiness we chose to live with. The comprises are the choices.
What if this was all there was to it.
Here is an interview with Noah Gift, CTO of Sqor SportsSports . He is a prolific coder in Python , R and Erlang. Since he is an expert coder in both R and Python, I decided to take his views on both. Noah is also the author of the book
Noah Gift is Chief Technical Officer and General Manager of Sqor. In this role, Noah is responsible for general management, product development and technical engineering. Prior to joining Sqor, Noah led Web Engineering at Linden Lab. He has B.S. in Nutritional Science from Cal Poly S.L.O, an Master’s degree in Computer Information Systems from CSULA, and an MBA from UC Davis. You can read more on him here
Related-
Some Articles on Python by Noah
Cloud business analytics: Write your own dashboard
Data science in the cloud Investment analysis with IPython and pandas
Linear optimization in Python, Part 1: Solve complex problems in the cloud with Pyomo
Linear optimization in Python, Part 2: Build a scalable architecture in the cloud
Using Python to create UNIX command line tools
I just got published on KDNuggets for a guest blog at http://www.kdnuggets.com/2015/12/using-python-r-together.html – I list down the reasons to moving to using both Python and R (not just one) and the current technology for the same. I think the R project could greatly benefit if the huge Python community came closer to using R language, and Python developers could greatly benefit from using R packages
An extract is here-
Using Python and R together: 3 main approaches
Both languages borrow from each other. Even seasoned package developers like Hadley Wickham (Rstudio) borrows from Beautiful Soup (python) to make rvest for web scraping.Yhat borrows from
sqldfto make pandasql. Rather than reinvent the wheel in the other language developers can focus on innovation
The customer does not care which language the code was written, the customer cares for insights.
To read the complete article … see
http://www.kdnuggets.com/2015/12/using-python-r-together.html

A National Security Agency (NSA) data gathering facility is seen in Bluffdale, about 25 miles south of Salt Lake City, Utah May 18. Technology holds the power to discover terrorism suspects from data—and yet to also safeguard privacy even with bulk telephone and email data intact, the author argues.
I must disagree with my fellow liberals. The NSA bulk data shutdown scheduled for November 29 is unnecessary and significantly compromises intelligence capabilities. As recent tragic events in Paris and elsewhere turn up the contentious heat on both sides of this issue, I’m keenly aware that mine is not the usual opinion for an avid supporter of Bernie Sanders (who was my hometown mayor in Vermont).
But as a techie, a former Columbia University computer science professor, I’m compelled to break some news: Technology holds the power to discover terrorism suspects from data—and yet to also safeguard privacy even with bulk telephone and email data intact. To be specific, stockpiling data about innocent people in particular is essential for state-of-the-art science that identifies new potential suspects.
I’m not talking about scanning to find perpetrators, the well-known practice of employing vigilant computers to trigger alerts on certain behavior. The system spots a potentially nefarious phone call and notifies a heroic agent—that’s a standard occurrence in intelligence thrillers, and a common topic in casual speculation about what our government is doing. Everyone’s familiar with this concept.
Rather, bulk data takes on a much more difficult, critical problem: precisely defining the alerts in the first place. The actual “intelligence” of an intelligence organization hinges on the patterns it matches against millions of cases—it must develop adept, intricate patterns that flag new potential suspects. Deriving these patterns from data automatically, the function of predictive analytics, is where the scientific rubber hits the road. (Once they’re established, matching the patterns and triggering alerts is relatively trivial, even when applied across millions of cases—that kind of mechanical process is simple for a computer.)
 It may seem paradoxical, but data about the innocent civilian can serve to identify the criminal. Although the ACLU calls it “mass, suspicionless surveillance,” this data establishes a baseline for the behavior of normal civilians. That is to say, law enforcement needs your data in order to learn from you how non-criminals behave. The more such data available, the more effectively it can do so.
It may seem paradoxical, but data about the innocent civilian can serve to identify the criminal. Although the ACLU calls it “mass, suspicionless surveillance,” this data establishes a baseline for the behavior of normal civilians. That is to say, law enforcement needs your data in order to learn from you how non-criminals behave. The more such data available, the more effectively it can do so.
This Newsweek article, originally published in Newsweek’s opinion section and excerpted here, resulted from the author’s research for a new extended sidebar on the topic that will appear in the forthcoming Revised and Updated, paperback edition of Eric Siegel’s Predictive Analytics: The Power to Predict Who Will Click, Buy, Lie, or Die (coming January 6, 2016).

