
Quandl just came up with a list of seven deadly sins for Data Scientists. Their site provides a wide collection of data that would be beneficial for anyone looking to become successful in the analytical field. I interviewed their founder some time back here
I would add lack of reading as the biggest sin, and lack of writing /blogging as a big sin too. I guess that would be covered in Sloth.

Some terms that a data scientist should not be slothful about learning
Overfitting-
Overfitting occurs when a statistical model describes random error or noise instead of the underlying relationship. Overfitting generally occurs when a model is excessively complex, such as having too many parameters relative to the number of observations
What it leads to- Model explains your existing data fine but wont work on fresh data
Lift–
lift is a measure of the performance of a targeting model (association rule) at predicting or classifying cases as having an enhanced response (with respect to the population as a whole), measured against a random choice targeting model. A targeting model is doing a good job if the response within the target is much better than the average for the population as a whole. Lift is simply the ratio of these values: target response divided by average response.
For example, suppose a population has an average response rate of 5%, but a certain model (or rule) has identified a segment with a response rate of 20%. Then that segment would have a lift of 4.0 (20%/5%).
Typically, the modeller seeks to divide the population into quantiles, and rank the quantiles by lift.
Hosmer-Lemeshow Goodness-of-Fit Test
The Hosmer–Lemeshow test is a statistical test for goodness of fit for logistic regression models. It is used frequently in risk prediction models. The test assesses whether or not the observed event rates match expected event rates in subgroups of the model population. The Hosmer–Lemeshow test specifically identifies subgroups as the deciles of fitted risk values. Models for which expected and observed event rates in subgroups are similar are called well calibrated.
First, the observations are sorted in increasing order of their estimated event probability. The event is the response level specified in the response variable option EVENT=, or the response level that is not specified in the REF= option, or, if neither of these options was specified, then the event is the response level identified in the “Response Profiles” table as “Ordered Value 1”. The observations are then divided into approximately 10 groups according to the following scheme.
Bayes Theorem
Bayes’ theorem is stated mathematically as the following equation:[2]
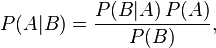
where A and B are events.
- P(A) and P(B) are the probabilities of A and B without regard to each other.
- P(A | B), a conditional probability, is the probability of observing event A given that B is true.
- P(B | A) is the probability of observing event B given that A is true.
Examples
Cancer at age 65
Suppose we want to know an individual’s probability of having cancer, but we know nothing about them. Despite not knowing anything about that person, a probability can be assigned based on the general prevalence of cancer. For the sake of this example, suppose it is 1%. This is known as the base rate or prior probability of having cancer. “Prior” refers to the time before being informed about the particular case at hand.
Next, suppose we find out that person is 65 years old. If we assume that cancer and age are related, this new piece of information can be used to better assess that person’s risk of having cancer. More precisely, we’d like to know the probability that a person has cancer when it is known that they are 65 years old. This quantity is known as the current probability, where “current” refers to the theorised situation upon finding out information about the particular case at hand.
In order to apply knowledge of that person’s age in conjunction with Bayes’ Theorem, two additional pieces of information are needed. Note, however, that the additional information is not specific to that person. The needed information is as follows:
- The probability of being 65 years old. Suppose it is 0.2%
- The probability that a person with cancer is 65 years old. Suppose it is 0.5%. Note that this is greater than the previous value. This reflects that people with cancer are disproportionately 65 years old.
Knowing this, along with the base rate, we can calculate that a person who is age 65 has a probability of having cancer equal to

Gradient Descent for Machine Learning
tochastic gradient descent (often shortened in SGD) is a stochastic approximation of the gradient descent optimizationmethod for minimizing an objective function
Both statistical estimation and machine learning consider the problem of minimizing an objective function that has the form of a sum:

where the parameter 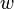 which minimizes
which minimizes 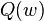 is to be estimated. Each summand function
is to be estimated. Each summand function  is typically associated with the
is typically associated with the  -th observation in the data set (used for training).
-th observation in the data set (used for training).
In classical statistics, sum-minimization problems arise in least squares and in maximum-likelihood estimation (for independent observations).
https://www.coursera.org/learn/machine-learning/lecture/kCvQc/gradient-descent-for-linear-regression

Source
https://en.wikipedia.org/wiki/Lift_(data_mining)
http://www.newyorker.com/culture/culture-desk/remembering-prince
https://en.wikipedia.org/wiki/Bayes%27_theorem
https://en.wikipedia.org/wiki/Overfitting
https://support.sas.com/documentation/cdl/en/statug/63033/HTML/default/statug_logistic_sect039.htm
https://en.wikipedia.org/wiki/Hosmer%E2%80%93Lemeshow_test
