RStudio is the clear market leader in IDE used by developers for R data science.
R is the clear market leader for data science.
Python can do with more wrappers for R like packages.
But Jupyter is awesome (once you get it working!)
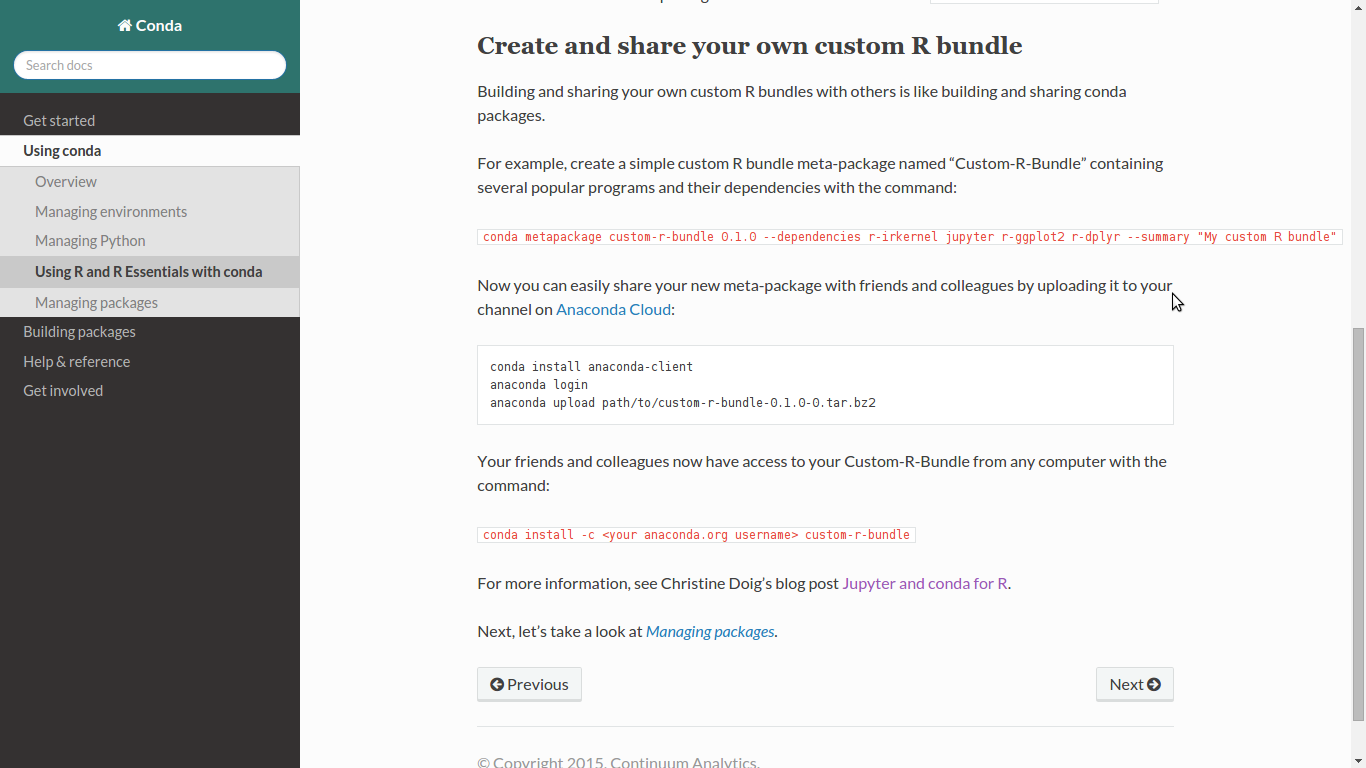
Hopefully, multi core stuff and cloud hosted stuff should be easy too. Google Cloud Data Labs with hosted Jupyter is just the first step. see https://cloud.google.com/datalab/
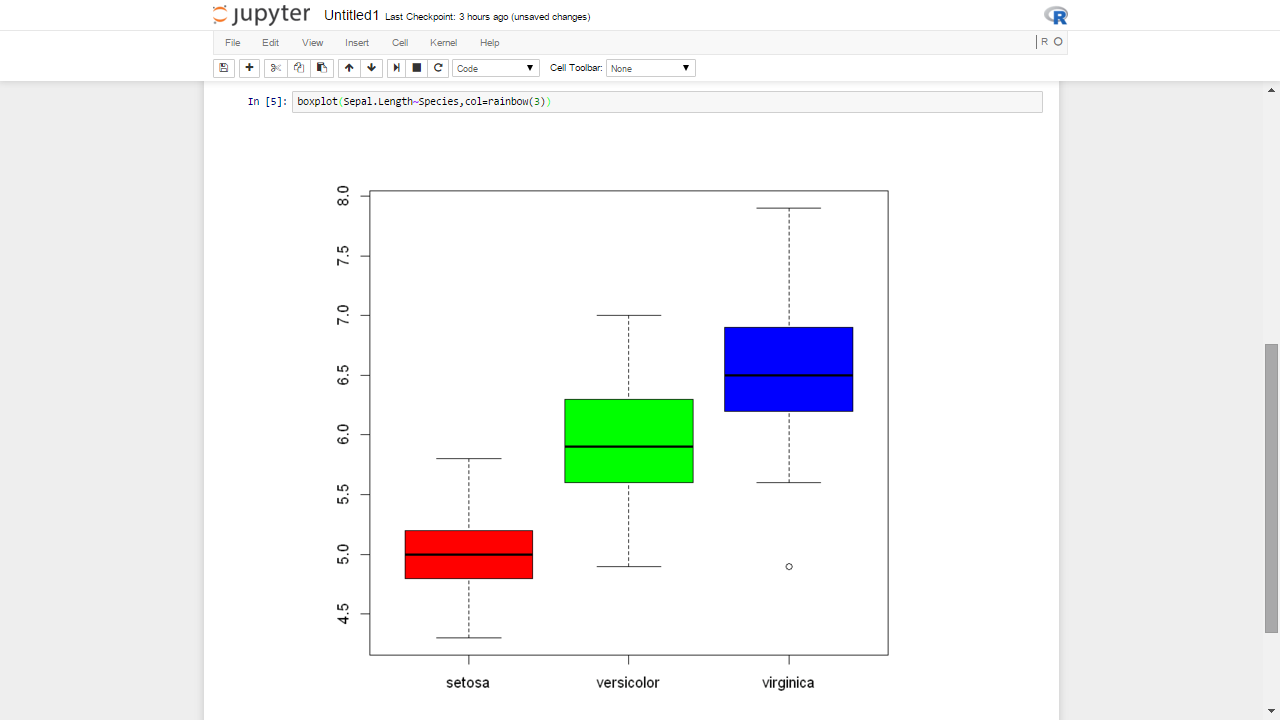
One of the best things I like about Jupyter OVER RStudio’s interface is the ability to divide code blocks in cells. In addition the ability to install new packages from with RSTUDIO really helps me over the Jupyter. The syntax prompt in latest version of RSTUDIO is something I wish JUPYTER really worrks on.
Can we have a RSTUDIO like interface to working with Python. Yes Yhat made one and called it RODEO. This is because the interface is based on the ACE editor ( yes esseentially RStdudio the company married ACE Editor to Hadley Wickham to get RSTUDIO the product 😉 . Shiny was wonderful but for scalable data science Python and Java help me just as much as R does for BIg DATA ANALYSIS) Scalability is the key here! Rpubs isnt as popular as NBviewer is and now we can wrap markdown within a Jupyter notebook

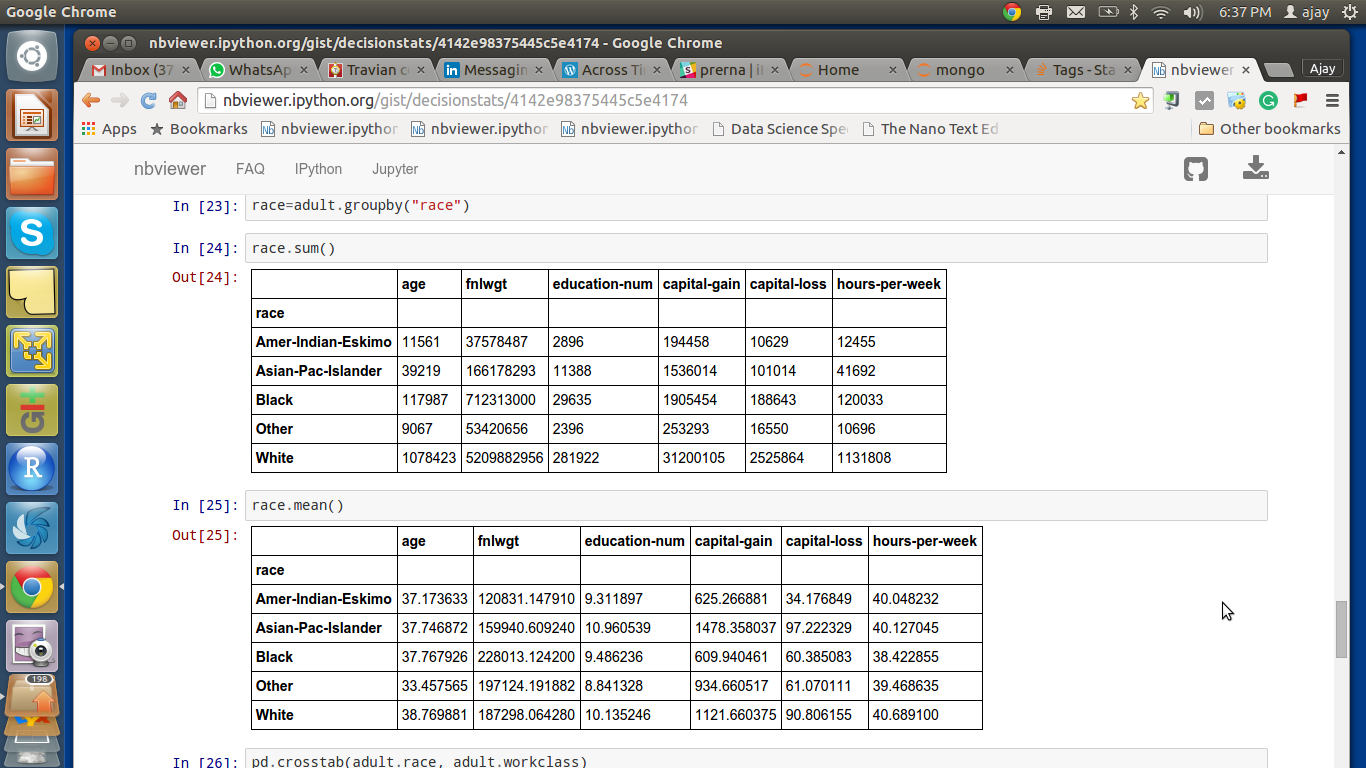
can Jupyter help in my data science work more than RStudio? These are early days but I prefer a cross platform cross language ( Julia, Python and R) solution anyday. Provided it works just as seamlessly than the established market leader RStudio.
BIG DATA ANALYTICS is where I clearly see JUPYTER help data scientists more than RStdudio as you can use the IRKERNEL. I am especially hoping to see the Spark Kernel , JS Kernel https://www.npmjs.com/package/ijavascript and others be more production ready for business enterprises.
https://github.com/ibm-et/spark-kernel
https://github.com/ipython/ipython/wiki/IPython-kernels-for-other-languages
Python/Jupyter kernels:
The Kernel Zero, is of course IPython, which you can get though ipykernel, and still comes (for now) as a dependency of jupyter. The IPython kernel can be thought as a reference implementation, here are other available kernels:
| Name | Link | Jupyter/IPython Version | Language(s) Version | 3rd party dependencies |
|---|---|---|---|---|
| ICSharp | https://github.com/zabirauf/icsharp | Jupyter 4.0 | C# 4.0+ | scriptcs |
| IRKernel | http://irkernel.github.io/ | IPython 3.0 | R 3.2 | rzmq |
| SageMath | http://www.sagemath.org/ | IPython 3.2 | Any |